I often get asked which Big Data computing environment should be chosen on Azure. The answer is heavily dependent on the workload, the legacy system (if any), and the skill set of the development and operation teams. Here is a (necessarily heavily simplified) overview of the main options and decision criteria I usually apply.
Table of Contents
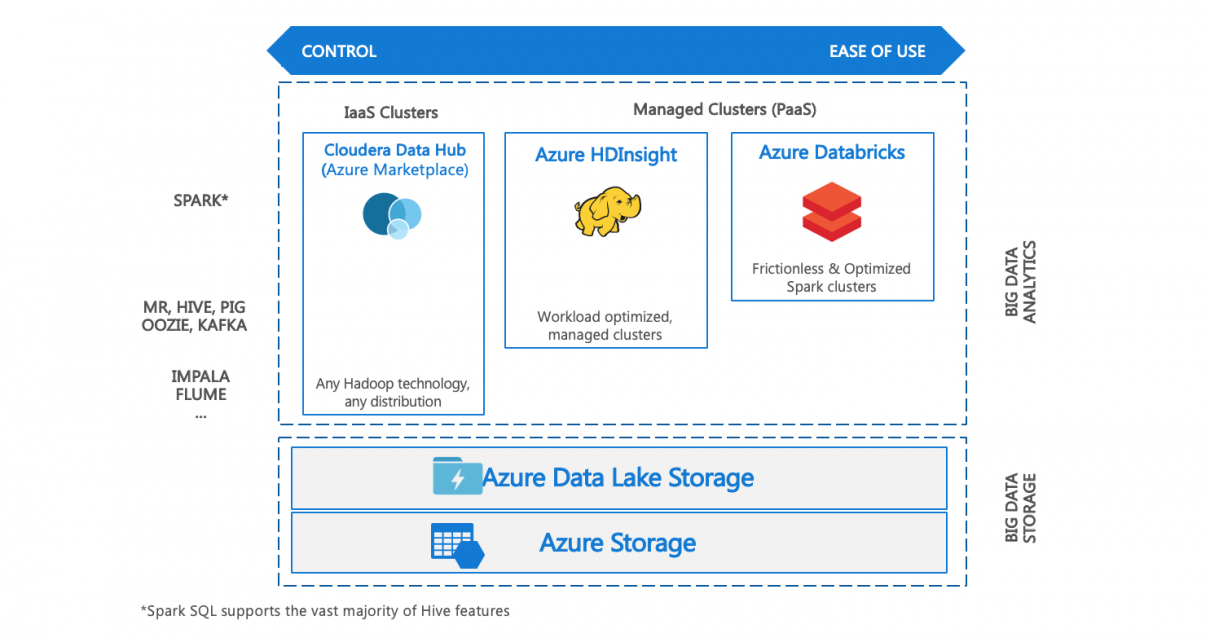
Hadoop on VMs
Cloudera Data Hub is a distribution of Hadoop running on Azure Virtual Machines. It can be deployed through the Azure marketplace.
Cloudera Data Hub is designed for building a unified enterprise data platform. Its Enterprise features include:
- Full hybrid support & parity with on-premises Cloudera deployments
- Ranger support (Kerberos-based Security) and fine-grained authorization (Sentry)
Pros
- Widest portfolio of Hadoop technologies
- Single platform serving multiple applications seamlessly on-premises and on-cloud
Cons
- Dedicated infrastructure team to manage, configure and patch the infrastructure (OS, platform)
- Limited ability to scale on-demand
- Not designed for hosting single workloads
- Separate vendor management
For more information, refer to the Cloudera on Azure Reference Architecture.
Azure HDInsight
HDInsight is a Hortonworks-derived distribution provided as a first party service on Azure. It supports the most common Big Data engines, including MapReduce, Hive on Tez, Hive LLAP, Spark, HBase, Storm, Kafka, and Microsoft R Server. It is aimed to provide a developer self-managed experience with optimized developer tooling and monitoring capabilities. Its Enterprise features include:
- Ranger support (Kerberos based Security)
- Log Analytics via OMS
- Orchestration via Azure Data Factory
Pros
- Most common Hadoop technologies available
- Open-source codebase
- Configurable via script actions
Cons
- Hortonworks stack is distinct from existing on-premises Cloudera
- Different clusters for Spark and Hive
- Need to manage workload-based scaling
- Delays in releasing new component versions
Azure Databricks
Databricks’ Spark service is a highly optimized engine built by the founders of Spark, and provided together with Microsoft as a first party service on Azure. It offers a single engine for Batch, Streaming, ML and Graph, and a best-in-class notebooks experience for optimal productivity and collaboration. Its Enterprise features include:
- Native Integration with Azure for Security via Azure AD (OAuth)
- Optimized engine for better performance and scalability
- Integrated Role-based Access Control for Notebooks and APIs
- Auto-scaling and automated cluster termination capabilities
- Native integration with SQL DW and other Azure services
- Serverless pools for easier management of resources
Pros
- Highly optimized Spark for cloud – typically 5x-10xfaster than open-source offering
- No management overhead
- Designed for integrating building data pipelines
- Highest developer/analyst productivity
Cons
- Higher per-minute cost (but usually offset by performance gains and optimization with autoscaling)
- Spark only
Summary
For cloud native development, Databricks shines as it was built from the group up for the enterprise cloud, and therefore provides the easiest path including robust security and outstanding performance.
For hybrid workloads, integrated products from vendors such as Cloudera Altus provide a relatively straightforward way to spin additional / transient environments on the cloud, limiting management complexity.
For the migration of legacy workloads to cloud, the various paths should be assessed for cost/benefit. Such migrations are often the occasion for an application modernization initiative. In that case, breaking apart a monolithic Hadoop setup into distinct Azure PaaS solutions often leads to improved maintainability and cost. Often, Azure Databricks together with other Azure PaaS products ends up to be the target of choice. As an illustration, here is perhaps the most common migration path for each Hadoop technology.
- Hive jobs can usually be run out of the box on Spark. Spark SQL supports vast majority of Hive query features.
- HBase can be replaced with Azure Table storage or Cosmos DB.
- Storm is legacy technology and can be replaced with Spark Streaming or serverless processing.
- MapReduce is legacy technology and can be replaced with Spark.
- Kafka doesn’t use the Hadoop stack, although Hadoop vendors have integrated it into their platform to allow unified management. Kafka can be deployed standalone in HDInsight, or replaced with a PaaS Event Hubs for Kafka (be aware of limitations in feature coverage and number of topics supported).
- Impala: in Databricks’s own published benchmarks, Databricks outperforms Impala. In the meantime, Databricks has introduced the additional key performance optimizations in Delta, their new data management system.
- Oozie/Airflow can be replaced with Azure Data Factory.
As an alternative, a Cosmos DB / Functions (serverless) architecture can sometimes be targeted when the workload is oriented toward single event processing.