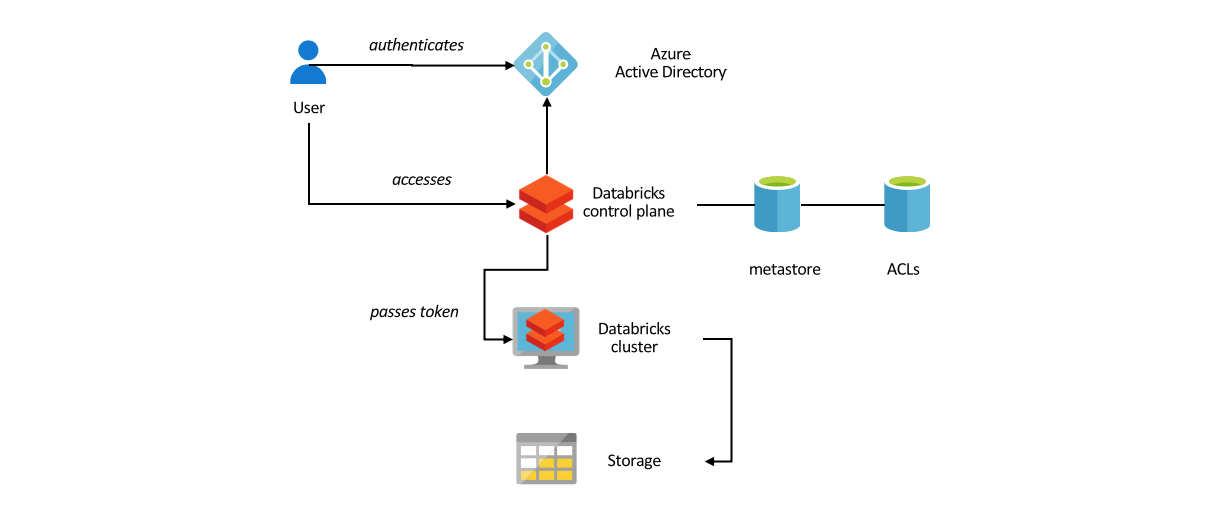
This is part 2 of our series on Databricks security, following Network Isolation for Azure Databricks.
The simplest way to provide data level security in Azure Databricks is to use fixed account keys or service principals for accessing data in Blob storage or Data Lake Storage. This grants every user of Databricks cluster access to the data defined by the Access Control Lists for the service principal. In cases when Databricks clusters are shared among multiple users who must have different access rights to the data, the following mechanisms can be used:
- Table Access Control
- Credential Passthrough
They have different scopes, but can be combined if needed.
Table of Contents
Table Access Control
Table access control allows granting access to your data using the Azure Databricks view-based access control model. Requirements and limitations for using Table Access Control include:
- Azure Databricks Premium tier.
- High concurrency clusters, which support only Python and SQL.
- Users may not have permissions to create clusters.
- Network connections to ports other than 80 and 443. This prevents for example connectivity to SQL Database, but not to Storage or Cosmos DB.
Azure Data Lake Storage credential passthrough
When accessing data stored in Azure Data Lake Storage (Gen1 or Gen2), user credentials can be seamlessly passed through to the storage layer. The following apply:
- Azure Databricks Premium tier.
- Databricks Runtime 5.3 or above. (With ADLS Gen1, Runtime 5.1 or above.)
- High concurrency clusters, which support only Python and SQL.
- Data must be accessed directly using an abfss:// or adls:// path, or through a special DBFS mount point.
- You may not have the Data Lake Storage mounted to any DBFS mount point with a standard DBFS mount (with credentials). Otherwise those credentials will silently be used for other users, even when they provide an adls:// path!
- Additional limitations are documented at #adls-aad-credentials.
Credential passthrough is a particularly elegant mechanism as it allows centralizing data access controls on the storage layer, so that it can be applied whatever mechanism is used to access the data (from a compute cluster, through a client application, etc.)
Combining Table Access Control and Passthrough
Let us demonstrate how both mechanisms can complement each other.
To reproduce the examples below, create an ADLS Gen1 account. If you’re an Owner of the subscription, you will automatically have full access to the ADLS Gen1 content, also within Azure Databricks.
Create an Azure Databricks Premium tier workspace. Create a High Concurrency cluster and enable both Table Access Control and Credential Passthrough.
Generate a partitioned table in Parquet format stored on the ADLS account, using the following command in a Python notebook.
spark.read \
.option("header", True) \
.csv("/databricks-datasets/sfo_customer_survey/2013_SFO_Customer_Survey.csv") \
.write.partitionBy("AIRLINE") \
.option("path", "adl://MYADLSACCOUNT.azuredatalakestore.net/sfo_customer_survey") \
.mode("overwrite") \
.saveAsTable("sfo_customer_survey_adls")
Add another user to your Databricks workspace. Log on as that other user to the workspace. (Note that if the user does not have Reader permission on the Azure resource, she will not be able to log on through the Azure portal, but she can access the workspace through the control plane URL, e.g. https://northeurope.azuredatabricks.net/).
As Table Access Control is enabled, non-admin users don’t have access to tables by default:
As the admin user, you can grant permissions on tables:
The non-admin user now gets another different error, as she has not been granted access to the data within ADLS:
After assigning permissions to the data (i.e. Read and Execute to the folder and all its descendants) to the user, the non-admin user can issue a select query.
Implementing Row-Level Security
Given the above, it would appear that a form of ‘Row-Level Security’ (actually at a rough grain) can be implementing by preventing access to certain partitions on storage. That however doesn’t work. After removing access to one of the AIRLINE partition folders, the user can’t access the data at all:
The user can still access the rest of the data, as long as the query only accesses data the user has access to (through partition elimination with filter queries):
To restrict the set of rows and/or columns that a user can access, or increasing the grain at which data is presented, you can use a view. Views have their own Access Control List, so a user can be granted access to a view without having access to the underlying table.
As the data is partitioned by Airline in storage, such a view definition can use partition elimination so that performance is not impacted. In other cases however, the application of the view definition will generate additional processing. You can materialize the view (i.e. output the view data to a separate table) to avoid this, but it introduces additional complexity to keep the data in sync.
If row-level access rules cannot be expressed in such a static form, multiple views can be created. For example, a company with 100 sales territories where associates should only see data from their territory will have to create and manage access to 100 views. This can quickly become unmanageable with multiple criteria or dynamic security rules. In that case the row-level security and column-level security features of Azure SQL Data Warehouse can be a better fit.
Notes
Thanks to Mike Cornell (Databricks), Mladen Kovacevic (Databricks), and Benjamin Leroux (Microsoft) for providing ideas and feedback for this post. Updated in April 2019 with ADLS Gen2 support.