Table of Contents
Scenario
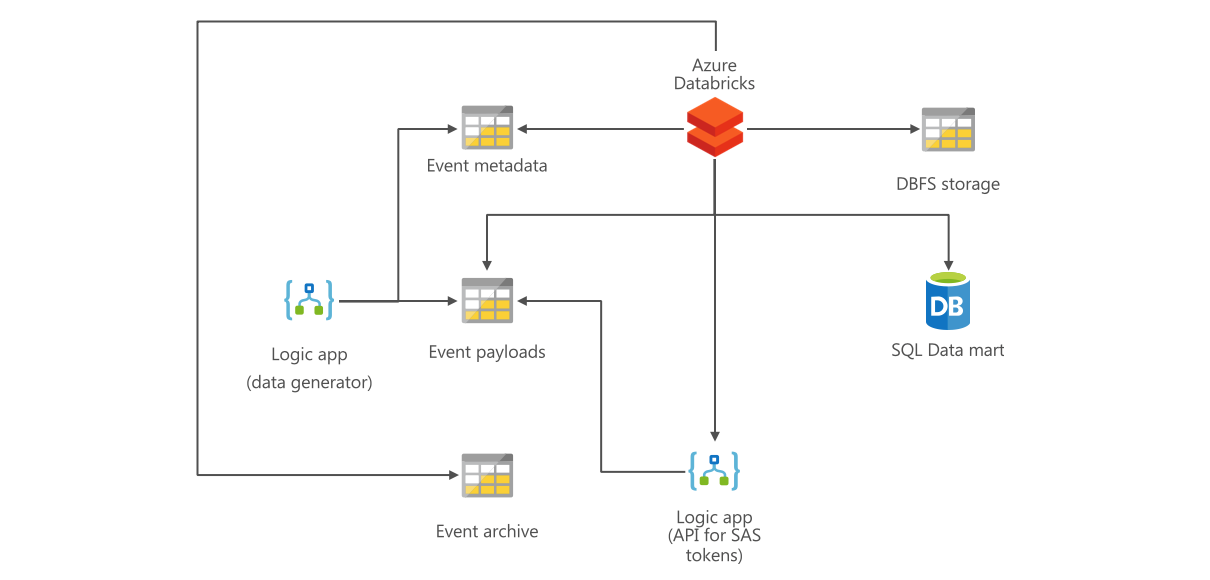
A data producer service generates data as messages. As messages can contain very large payloads, the service writes the data content to blob files, and only sends metadata as events.
The data producer service exposes an API allowing retrieval of the payload data. Rather than returning the payload data in the API response, the API sends back an SAS token allowing the caller to retrieve the payload data from the storage endpoint. The SAS token has a short time validity.
The events could be consumed in two ways:
- As streamed events, e.g. in Kafka or Event Hubs. The events can then be consumed using Structured Streaming. This is suitable for low latency processing.
- As data in blob storage. This is cost-effective for high latency processing.
In this tutorial, we will focus on the second scenario. This allows us to only spawn Databricks clusters at given time intervals, saving cost.
We will create a data generator that simulates the data producer service described above, and then a Spark application that consumes the incoming events from blob storage, applies idempotent processing to determine which payloads are new or have a changed checksum, calls the API to retrieve the SAS tokens, and retrieves the payloads.
Creating the data generator
We will create a Logic App that will run every minute and create several dummy message files and object files.
Create a Storage Account. In the Storage Account, navigate to Blobs and create three new Containers called:
- indata
- indataprocessed
- objects
Navigate to the Storage Account Access Keys, and copy the key1 Key value to Notepad or similar. Also take note of the Storage Account name.
Create a new Logic App named “generator”.
Select the Recurrence trigger. Then add an action of type Azure Blob Storage, Create blob. Name the connection azureblob. Switch to Code View. Keep the connections block as-is, and replace the definition block with the following.
"definition": {
"$schema": "https://schema.management.azure.com/providers/Microsoft.Logic/schemas/2016-06-01/workflowdefinition.json#",
"actions": {
"Create_blob": {
"inputs": {
"body": "{\"id\":\"@{variables('filename')}1\",\"DataId\":\"@{variables('filename')}\", \"DataFingerprint\":\"@{variables('filename')}\",\"DataTimestamp\":\"@{utcNow()}\"}",
"host": {
"connection": {
"name": "@parameters('$connections')['azureblob']['connectionId']"
}
},
"method": "post",
"path": "/datasets/default/files",
"queries": {
"folderPath": "/indata",
"name": "@{variables('filename')}1.json",
"queryParametersSingleEncoded": true
}
},
"runAfter": {
"Initialize_variable": [
"Succeeded"
]
},
"runtimeConfiguration": {
"contentTransfer": {
"transferMode": "Chunked"
}
},
"type": "ApiConnection"
},
"Create_blob_2": {
"inputs": {
"body": "{\"id\":\"@{variables('filename')}1\",\"DataId\":\"@{variables('filename')}\", \"DataFingerprint\":\"123456\",\"DataTimestamp\":\"@{utcNow()}\"}",
"host": {
"connection": {
"name": "@parameters('$connections')['azureblob']['connectionId']"
}
},
"method": "post",
"path": "/datasets/default/files",
"queries": {
"folderPath": "/indata",
"name": "@{variables('filename')}2.json",
"queryParametersSingleEncoded": true
}
},
"runAfter": {
"Create_blob": [
"Succeeded"
]
},
"runtimeConfiguration": {
"contentTransfer": {
"transferMode": "Chunked"
}
},
"type": "ApiConnection"
},
"Create_blob_3": {
"inputs": {
"body": "{\"filedata\":\"@{rand(1,10000)}\"}",
"host": {
"connection": {
"name": "@parameters('$connections')['azureblob']['connectionId']"
}
},
"method": "post",
"path": "/datasets/default/files",
"queries": {
"folderPath": "/objects",
"name": "@variables('filename')",
"queryParametersSingleEncoded": true
}
},
"runAfter": {
"Create_blob_2": [
"Succeeded"
]
},
"runtimeConfiguration": {
"contentTransfer": {
"transferMode": "Chunked"
}
},
"type": "ApiConnection"
},
"Current_time": {
"inputs": {},
"kind": "CurrentTime",
"runAfter": {},
"type": "Expression"
},
"Initialize_variable": {
"inputs": {
"variables": [
{
"name": "filename",
"type": "String",
"value": "@{replace(body('Current_time'), ':', '')}"
}
]
},
"runAfter": {
"Current_time": [
"Succeeded"
]
},
"type": "InitializeVariable"
}
},
"contentVersion": "1.0.0.0",
"outputs": {},
"parameters": {
"$connections": {
"defaultValue": {},
"type": "Object"
}
},
"triggers": {
"Recurrence": {
"recurrence": {
"frequency": "Minute",
"interval": 1
},
"type": "Recurrence"
}
}
}
Creating the API
Again, create another Logic App called api. As Trigger, select “When a HTTP request is received”. Click “Use sample payload to generate schema”. As sample payload, paste the following:
{
"DataId": "1234"
}
Copy the HTTP POST URL to your Notepad.
Add an action “Create SAS URI by path”. As blob path “/objects/DataId”, copying the DataId field from the Dynamic content window. As permissions, select Read.
Add an action “Response”. As body select the Shared access signature from the previous action.
Save the Logic App definition.
Creating the Databricks notebook
Create a new SQL Notebook called 10-create-tables.
-- Creates a native parquet table
CREATE TABLE IF NOT EXISTS seen_data_ids (DataId STRING, DataFingerprint STRING)
USING PARQUET
Create a new Scala Notebook called 20-mount-storage. Paste the following code in the notebook. Replace three times ACCOUNT with your storage account name, and STORAGEACCOUNTKEY with the storage account key you copied before.
val credentials = Map("fs.azure.account.key.ACCOUNT.blob.core.windows.net" ->
"STORAGEACCOUNTKEY")
if (!dbutils.fs.mounts.map(mnt => mnt.mountPoint).contains("/mnt/apietl/indata"))
dbutils.fs.mount(
source = "wasbs://indata@ACCOUNT.blob.core.windows.net/",
mountPoint = "/mnt/apietl/indata",
extraConfigs = credentials)
if (!dbutils.fs.mounts.map(mnt => mnt.mountPoint).contains("/mnt/apietl/indataprocessed"))
dbutils.fs.mount(
source = "wasbs://indataprocessed@ACCOUNT.blob.core.windows.net/",
mountPoint = "/mnt/apietl/indataprocessed",
extraConfigs = credentials)
Create a new Scala notebook called 30-consume-data. Copy the following content into your notebook (one block per cell). Execute each cell, one at a time, and make sure you understand the logic. Replace TRIGGERURL with the URL to your Logic App HTTP trigger.
import java.io._ import org.apache.commons._ import org.apache.http._ import org.apache.http.client._ import org.apache.http.client.methods.HttpGet import org.apache.http.client.methods.HttpPost import org.apache.http.impl.client.CloseableHttpClient import org.apache.http.impl.client.HttpClientBuilder import java.io.IOException import org.apache.http.impl.client.BasicResponseHandler import java.util.ArrayList import org.apache.http.message.BasicNameValuePair import org.apache.http.client.entity.UrlEncodedFormEntity import org.apache.http.client.entity.EntityBuilder import com.google.gson.Gson case class Payload(dataId: String) def getSASToken( dataId : String ) : String = { val httpClient = HttpClientBuilder.create.build val gson = new Gson() // create our object as a json string val payload = new Payload(dataId) val payloadAsJson = gson.toJson(payload) // add name value pairs to a post object val post = new HttpPost("TRIGGERURL") post.setEntity(EntityBuilder.create.setText(payloadAsJson).build) post.setHeader("Accept", "application/json") post.setHeader("Content-Type", "application/json") // send the post request val responseAsJson = httpClient.execute(post, new BasicResponseHandler) val response = gson.fromJson(responseAsJson, classOf[java.util.Map[String,String]])//new java.util.HashMap[String,String]().getClass) return response.get("WebUrl") } def downloadObject( dataId : String ) : String = { val httpClient = HttpClientBuilder.create.build val sasToken = getSASToken(dataId) val httpget = new HttpGet(sasToken) val responseAsString = httpClient.execute(httpget, new BasicResponseHandler) return responseAsString } spark.udf.register("downloadObject", downloadObject _)
val inputPath = "/mnt/apietl/indata"
val processedPath = "/mnt/apietl/indataprocessed"
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
// Since we know the data format already, let's define the schema to speed up processing (no need for Spark to infer schema)
val jsonSchema = new StructType().add("id", StringType).add("DataId", StringType).add("DataFingerprint", StringType).add("DataTimestamp", TimestampType)
spark
.read
.schema(jsonSchema)
.json(inputPath)
.withColumn("filename", input_file_name)
.cache
.createOrReplaceTempView("indata")
%sql REFRESH TABLE indata
%sql
SELECT * FROM indata
%sql
CREATE OR REPLACE TEMPORARY VIEW data_grouped AS
WITH latest_data AS
(
SELECT DataId, max(DataTimestamp) AS DataTimestamp
FROM indata
GROUP BY DataId
)
SELECT DataId, max(DataFingerprint) AS DataFingerprint
FROM indata
JOIN latest_data USING (DataId, DataTimestamp)
GROUP BY DataId, DataTimestamp -- resolve tied DataTimestamp
;
SELECT * FROM data_grouped
%sql
CREATE OR REPLACE TEMPORARY VIEW data_new AS
SELECT *
FROM data_grouped
LEFT ANTI JOIN seen_data_ids USING (DataId, DataFingerprint)
;
CACHE TABLE data_new;
SELECT * FROM data_new
%sql
CREATE OR REPLACE TEMPORARY VIEW data_new_objects AS
SELECT *,
downloadObject(DataId) AS objectContent
FROM data_new
;
CACHE TABLE data_new_objects;
SELECT * FROM data_new_objects;
%sql
CREATE OR REPLACE TEMPORARY VIEW etl_data AS
SELECT indata.*, data_new_objects.objectContent
FROM indata
LEFT JOIN data_new_objects USING (DataId)
;
CACHE TABLE etl_data;
SELECT * FROM etl_data;
spark.table("indata").select("filename").foreach(x => dbutils.fs.mv(x.getString(0), processedPath))
spark.table("data_new").write.mode("append").saveAsTable("seen_data_ids")
Exercises
(1) You will see the etl_data table contains the objectContent as a JSON string. Create a new View called etl_data_parsed with the value of the filedata element into a column. Hint:
- Spark SQL to parse a JSON string {‘keyName’:’value’} into a struct: from_json(jsonString, ‘keyName string’).filedata as filedata from etl_data;
- Spark SQL to extract a field fieldName from a struct S: SELECT S.fieldName
(2) Create an Azure SQL Database and write the etl_data_parsed content to a SQL database table. Use append mode. You have two options:
- Standard JDBC connector: #write-data-to-jdbc
- High performance Spark connector for Azure SQL Database (recommended): #write-to-azure-sql-database-or-sql-server
(3) Create an Azure Data Factory and create a pipeline to execute your Databricks notebook on a schedule (e.g. every 5 minutes).
(4) Produce a new column that computes the time since last event (difference of DataTimestamp by id). For this, change the control table (seen_data_ids) to a Delta table, add a LastTimestamp column to it, and implement upsert logic. See for an introduction to Databricks Delta.