Table of Contents
Cloud-native streaming architecture
Overview
Modern data analytics architectures should embrace the high flexibility required for today’s business environment, where the only certainty for every enterprise is that the ability to harness explosive volumes of
data in real time is emerging as a a key source of competitive advantage. Fortunately, cloud platforms allow high scalability and cost efficiency, provided cloud-native architectural patterns are implemented. At a minimum,
an analytical solution should make no compromises on the following dimensions:
- Push ingestion: avoid the time and cost impact of polling data sources repeatedly for data, and the complexity of tracking what data was already processed.
- Low latency: ability to process data end-to-end in near-realtime. In cases where low latency is not initially needed, it is still usually desirable to have the ability to reduce latency in the future
without having to rearchitect the system.
- Cost efficiency: architectures should be able to scale to thousands of data points per second or more, but also efficiently scale down during ramp-up or off periods. When high latency is acceptable, data should be processed using ephemeral compute infrastructure that is only spun a few times per day.
- Fault tolerance: this is beyond the ability to recover the state a single component. Implementing end-to-end guarantees requires the processing component to correctly react to upstream failures, and mitigate impact of its recovery on the consistency of downstream delivered data.
- Single point of logic implementation: architectures that separate event and batch processing, such as the famous Lambda architecture, require a duplication of logic and are fiendishly difficult to implement consistently.
- Data flexibility: the architecture should adapt to very different types of data, from lightweight events to large binary payloads that require custom code to be applied on ingestion.
- Full-featured engine: for maximum efficiency on the dimensions of cost, latency and complexity, the entire data processing should be performed in a single go. The data processing engine should therefore support the full set of features required for modern data analytics including: flexible parsing of data formats, analytical processing, complex event processing, machine learning, and native connectivity to a variety of sources and sinks.
Up to the recent past, implementing such requirements would mean setting up complex and disparate components on a platform such as Hadoop and dealing with significant complexity in implementation and maintenance. The use of cloud-native managed platforms largely eliminates that complexity.
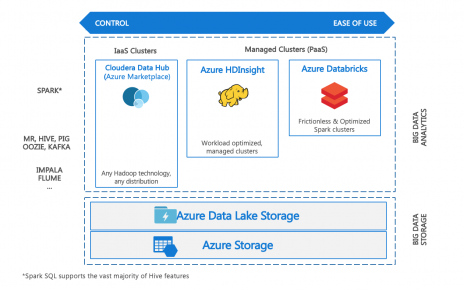
One key to achieving those requirements consistently lies is standardizing data processing jobs to run in a streaming manner, and use a stateful stream processing engine such as Spark to process the data. We will detail how this can be achieved using PaaS components on Azure.
Event Sourcing
Cloud-native components such as Blob Storage or Cosmos DB integrate the native ability to source events from data operations, and external source systems can usually be retrofitted to stream events directly into components such as Event Hub. Otherwise, you can use Blob Storage as an intermediate component. We cover event sourcing patterns in more detail below.
Structured Streaming
Spark Structured Streaming is an open-source streaming engine that allows focusing on implementing business logic. The engine manages the essential technical capabilities including:
- Providing end-to-end reliability and correctness guarantees
- Performing complex transformations
- Handling late or out-of-order data
- Integrating with other systems
Analytical engine
Databricks Delta is a next-generation unified analytics engine built on top of Apache Spark. Databricks Delta provides the components needed for an industrialised analytical engine, including ACID transactions, optimized data layouts and indexes, and features for stream processing into tables.
Thanks to fully featured Spark engine, advanced data transformations can be performed on the data at scale, such as analytical processing or machine learning.
Data Delivery
Although Databricks can expose query endpoints, the most effective way to deliver the data to consumers is usually to export it, for example to data marts of different forms optimized for specific access patterns. Databricks provide highly optimized connectors to deliver data in parallel at scale to enterprise database systems.
Event ingestion patterns
Data ingestion through Azure Storage
Data ingestion from Azure Storage is a highly flexible way of receiving data from a large variety of sources in structured or unstructured format. Azure Data Factory, Azure Logic Apps or third-party applications can deliver data from on-premises or cloud systems thanks to a large offering of connectors.
The ‘traditional’ approach to analytical data processing is to run batch processing jobs against data in storage at periodic interval. However, this is inefficient, as it requires repeated reading of storage metadata, and custom logic to handle duplication.
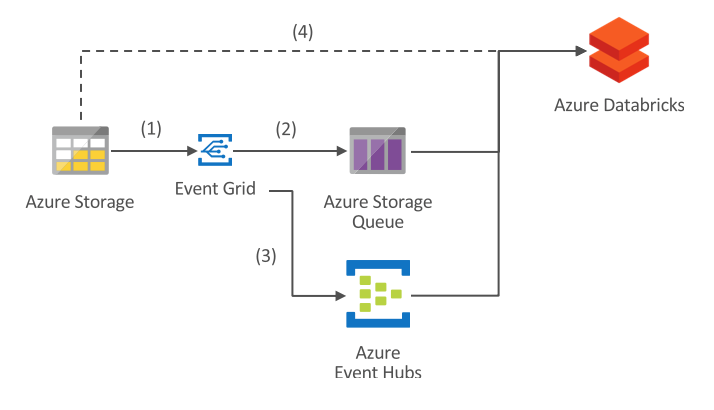
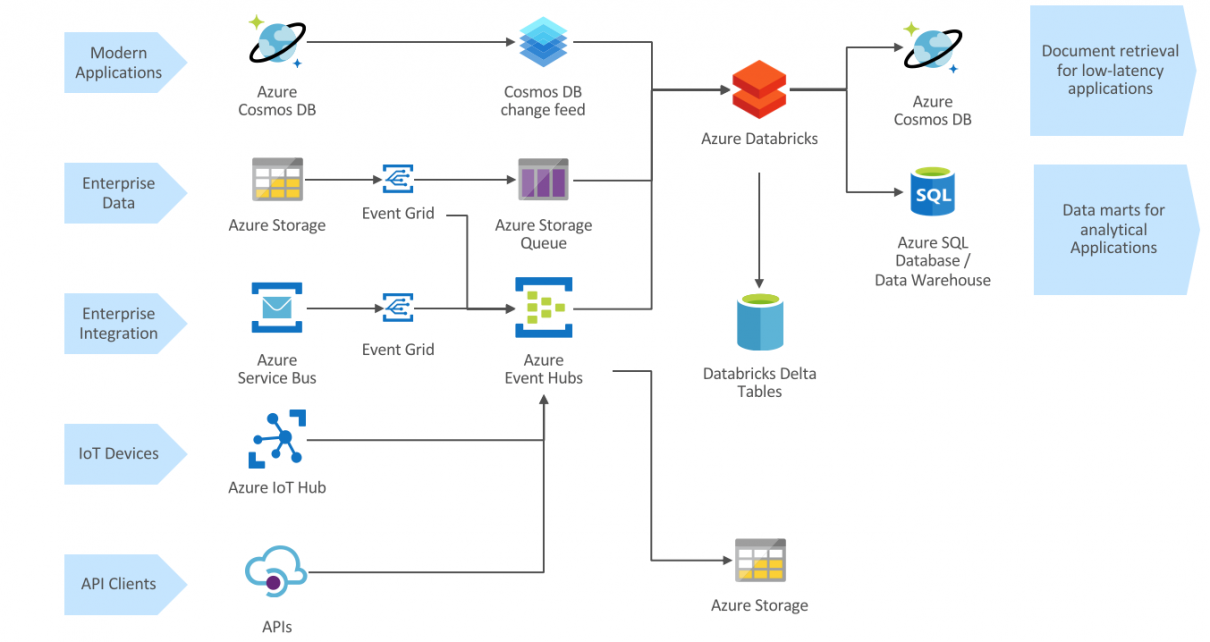
Azure Storage natively supports event sourcing, so that files written to storage can immediately trigger an event delivered into Azure Storage Queue or Event Hubs, marked by (1) in the image above.
- With Azure Storage Queue (2), you can use the optimized ABS-AQS Databricks connector to transparently consume the files from the storage source. The connector retrieves the file directly from storage and returns its content as binary.
- With Azure Event Hubs (3), you can use the Azure Event Hubs Databricks connector to retrieve the storage events. You can then access the storage account through a DBFS mount point, to retrieve the file content (4).
While processing storage events with Event Hubs is more complex than with the Queue Storage connector, the ability to write custom code for retrieving file data allows for writing custom logic. For example, if you need to retrieve only one element from a complex XML file, the ABS-AQS connector would retrieve the entire XML file into a Spark DataFrame that you would process later, while with the Event Hubs approach, you could extract the desired element while reading the data.
Event ingestion through Event Hubs or Cosmos DB
Azure Event Hubs is a highly scalable and effective event ingestion and streaming platform, that can scale to millions of events per seconds. It is based around the same concepts as Apache Kafka, but available as a fully managed platform. It also offers a Kafka-compatible API for easy integration with third-party components.
When source data can be represented and ingested in the form of streamed events, it is very compelling to streaming data directly to Event Hubs, either by connecting the source system directly or through an API layer (1). This allows low latency and high scalability. As Event Hubs only stores data for a limited time duration, the Event Hubs Capture mechanism can be used to store a copy of the events into permanent storage (2).
An compelling alternative design is to stream the events into Azure Cosmos DB (3). Through the Change Feed mechanism, Cosmos DB can effectively serve as an event sourcing feed. This is a very effective solution if the events are to be made available for online querying or as the glue layer of a serverless application.
Analytical processing layer
Spark Structured Streaming is a highly scalable. Although streaming is most commonly used for low-latency, always-on processing, it also lends itself to sporadic processing on ephemeral compute resources to reduce cost when higher latencies are sufficient.
Databricks Delta is a very efficient analytical engine for Spark, especially when used in streaming workloads. Some key features the engine provides are the ability to ingest streaming data directly into tables that are automatically managed and optimized, and the ability to use ‘upserts‘ (SQL MERGE commands) which are an essential capability of stream processing workloads and ETL processes in general.
The core logic can be expressed as simply as creating a Delta table and a MERGE statement as below. This can be extended with only the business logic needed to process the data. For instance, a Streaming Stock Data Analysis solution can be implemented in a few dozen lines of code. Partitioning, data management, error recovery are all performed automatically.
CREATE TABLE events (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING delta
PARTITIONED BY (date)
MERGE INTO events
USING updates
ON events.eventId = updates.eventId
WHEN MATCHED THEN
UPDATE SET
events.data = updates.data
WHEN NOT MATCHED
THEN INSERT (date, eventId, data) VALUES (date, eventId, data)
Data delivery
If the data will be accessed by point queries or short range queries with low latency, Cosmos DB is an excellent platform to achieve low-millisecond latencies with global geodistribution. One scenario would be precomputing shopping recommendations for the users of a retail website, and making them available in milliseconds when the user logs in. The Cosmos DB Spark Connector allows efficiently streaming large data volumes into (and out of) Cosmos DB.
When data will be retrieved through analytical processing engines, such as Business Intelligence applications, Azure SQL Database is an excellent platform. Here again, a Spark connector allows efficient parallel writes to SQL Database. When scaling to many terabytes and an MPP SQL engine is needed to process complex analytical transformations or perform additional data processing, Azure SQL Data Warehouse provides an alternative SQL engine.
Cost optimization
The first step to cost optimisation is to use managed services that scale on demand. For example, through the autoscaling mechanism, Azure Databricks clusters will automatically provision only the capacity needed to process the incoming workload at any given point in time.
By default, Spark Structured Streaming jobs run in continuous trigger mode, i.e. they will run the next microbatch immediately on completion (waiting for data to arrive is needed). An alternative is to use the RunOnce trigger to run a single ingestion batch and then complete the job. That pattern is particularly efficient when using ephemeral compute clusters, and end-to-end latency can be relatively high (at least 15 min).
Part 2 of this series is a tutorial on end-to-end event-based analytical processing.