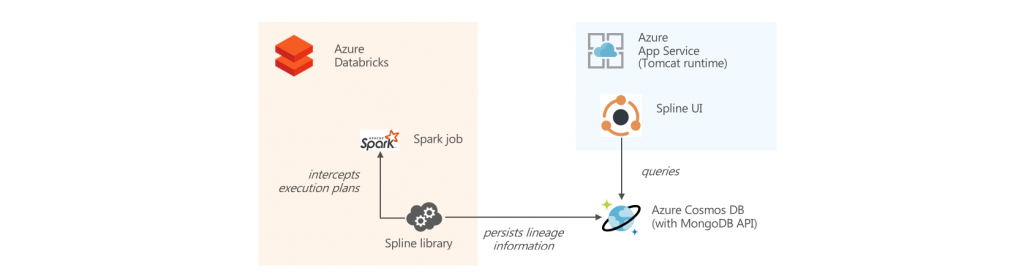
The Spline open-source project can be used to automatically capture data lineage information from Spark jobs, and provide an interactive GUI to search and visualize data lineage information. We provide an Azure DevOps template project that automates the deployment of an end-to-end demo project in your environment, using Azure Databricks, Cosmos DB and Azure App Service.
Table of Contents
Background
Data lineage is an essential aspect of data governance. The ability to capture for each dataset the details of how, when and from which sources it was generated is essential in many regulated industries, and has become ever more important with GDPR and the need for enterprises to manage ever growing amounts of enterprise data.
In the big data space, different initiatives have been proposed, but all suffer from limitations, vendor restrictions and blind spots. The open source project Spline aims to automatically and transparently capture lineage information from Spark plans. Spline is developed by ABSA (formerly Barclays), one of the largest African banks.
Data lineage and governance is a priority topic in many enterprises, and together with my colleague Arvind Shyamsundar, we are evaluating the complexity and benefits of integrating Spline into Azure Databricks environments.
The Spline project has several components:
- A library that runs on Spark and captures data lineage information
- A persistence layer that stores the data on MongoDB, HDFS or Atlas
- A Web UI application that visualizes the stored data lineages (supporting MongoDB)
We worked with the Spline development team to modify Spline to work when swapping the MongoDB backend with Cosmos DB, and testing the integration with Azure Databricks.
Walkthrough
Setting up the environment
To get started, you will need a Pay-as-you-Go or Enterprise Azure subscription. A free trial subscription will not allow you to create Databricks clusters.
Create an Azure Resource Group in a location of your choice.
Create an Azure Databricks workspace. Select a name and region of your choice. Select the standard tier.
Navigate to the Azure Databricks workspace. Generate a token and save it securely somewhere.
Navigate to and log in with your Azure AD credentials. Create a new Organization when prompted, or select an existing Organization if you’re already part of one.
Create a new Project.
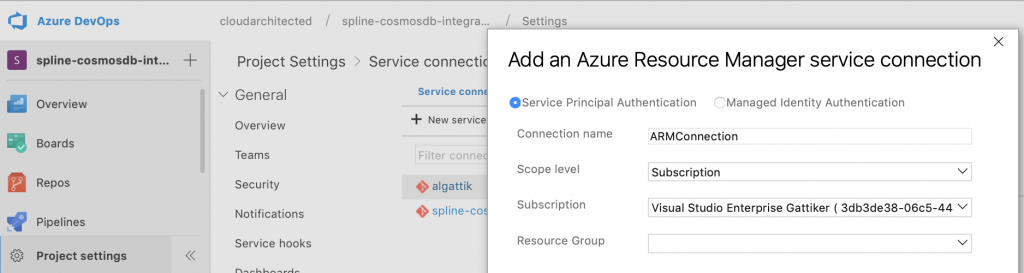
Navigate to Project settings > Service connections. Create a new service connection of type Azure Resource Manager. Name the connection ARMConnection. Select the subscription. Leave the resource group blank and click OK.
Navigate to Repos > Files, click the Import button and enter https://github.com/algattik/databricks-lineage-tutorial .
Creating the pipeline
Navigate to Pipelines > Builds, click New Pipeline, select Azure Repos Git and select your repository. The build pipeline definition file from source control (azure-pipelines.yml) opens. It contains a Maven task to build the latest version of the Spline UI, and scripts tasks to provision the environment and spin sample jobs.Set DATABRICKS_HOST and _TOKEN to the base URL of your Databricks workspace, and the token you created previously. Note: managing your token this way is insecure, in production you should use Azure Key Vault instead.
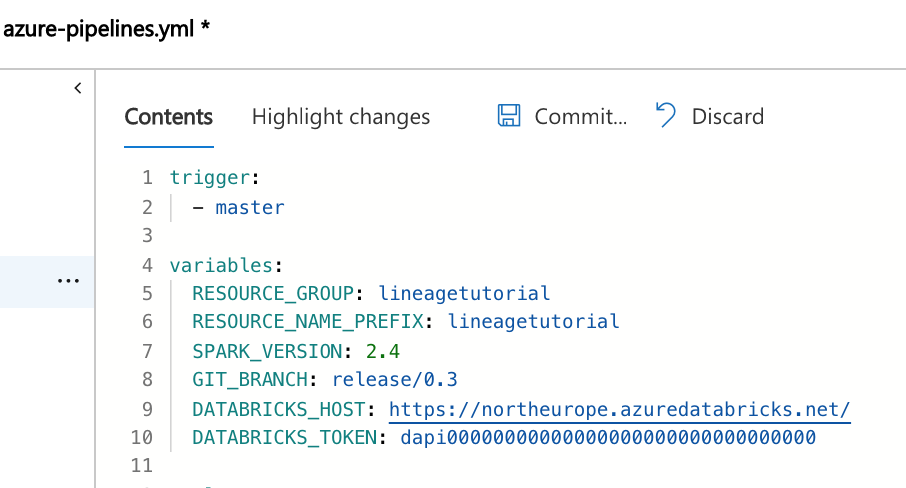
Click Commit to save the pipeline. Wait until the build runs to successful completion.
The build pipeline will provision a Cosmos DB instance and an Azure App Service webapp, build the Spline UI application (Java WAR file) and deploy it, install the Spline Spark libraries on Databricks, and run a Databricks job doing some data transformations in order to populate the lineage graph.
In Azure DevOps, navigate to the build pipeline run output. Locate the task named Display Webapp URL and click on it to visualize its output. Navigate to the displayed URL to view the Spline UI.
Databricks notebooks
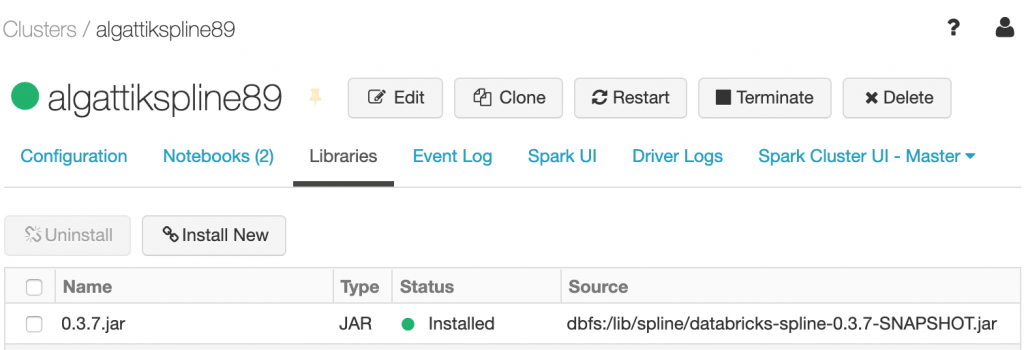
In Azure Databricks, navigate to the Clusters pane. The pipeline deploys a cluster that you can immediately use to test your own workload. The cluster automatically terminates after 2 hours. You can see the installed Spline library on the cluster Libraries tab.
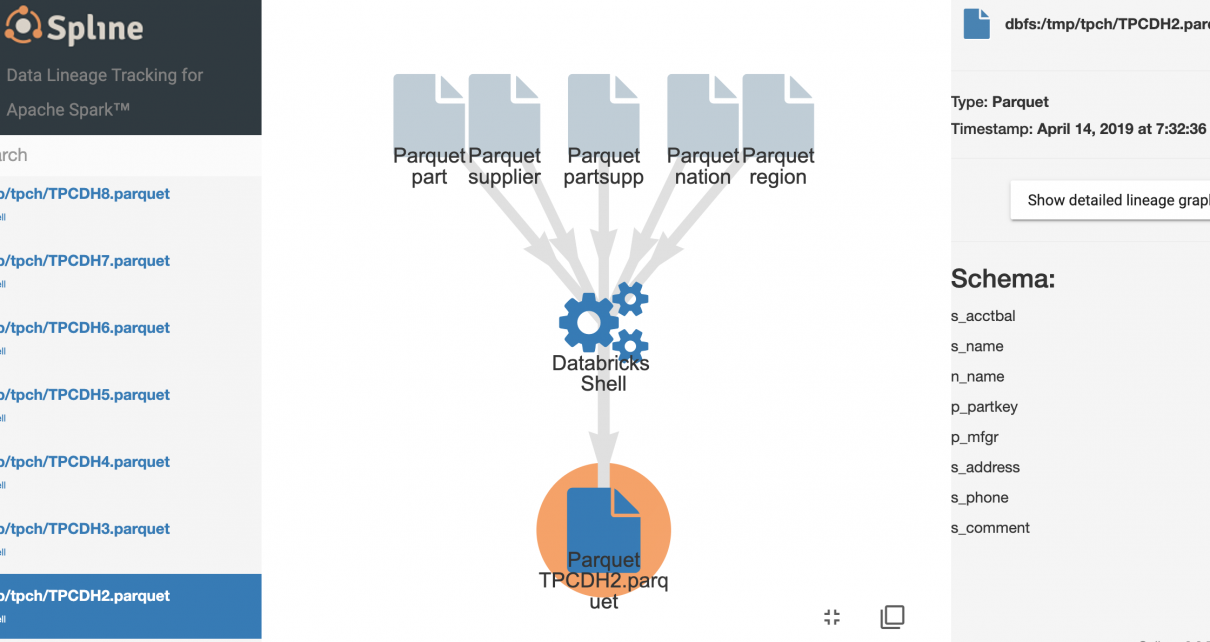
In Azure Databricks, navigate to the /Shared/databricks-lineage-tutorial/ workspace directory to view the two deployed sample notebooks. Open the TPC-H notebook which runs some queries from the industry-standard TPC-H benchmark.
After setting the required properties for Spline to capture lineage, the notebook runs a number of queries. Lineage is automatically captured and stored.
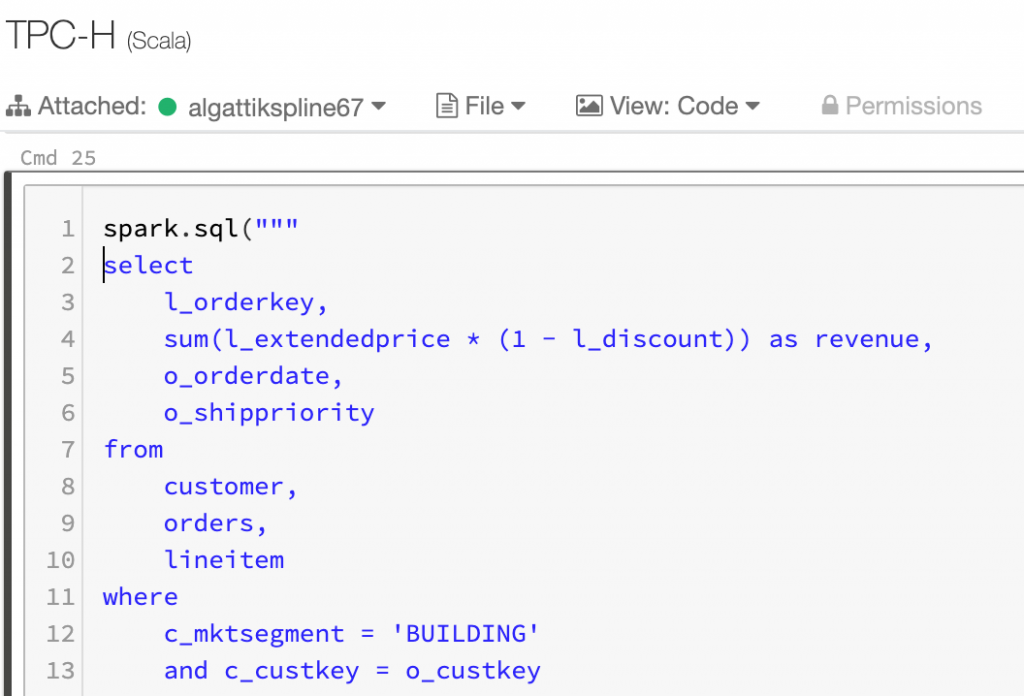
Spline UI
Note that the Spline UI webapp is deployed without any security. Modify the sample project to enable authentication if required.
Click on any job to view its lineage.
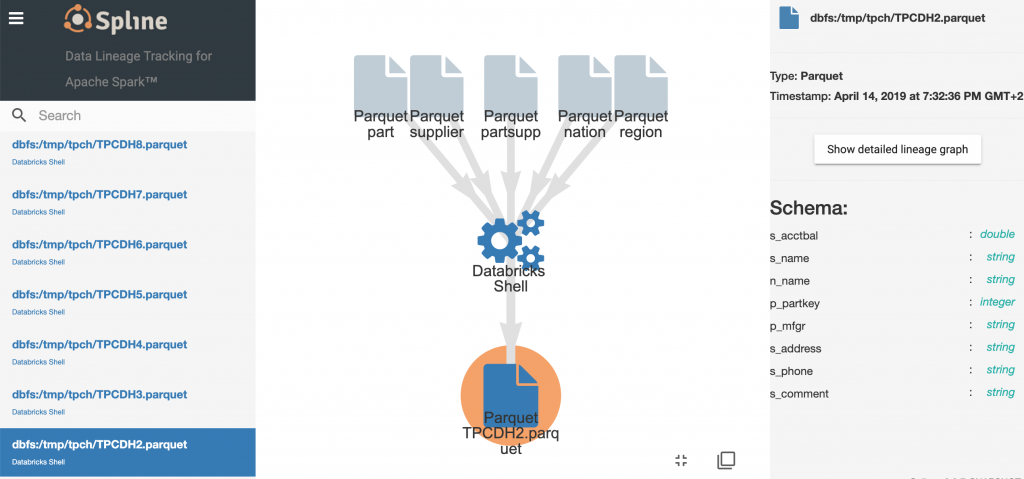
Double-click on the cogwheels to view the detailed Spark job graph.
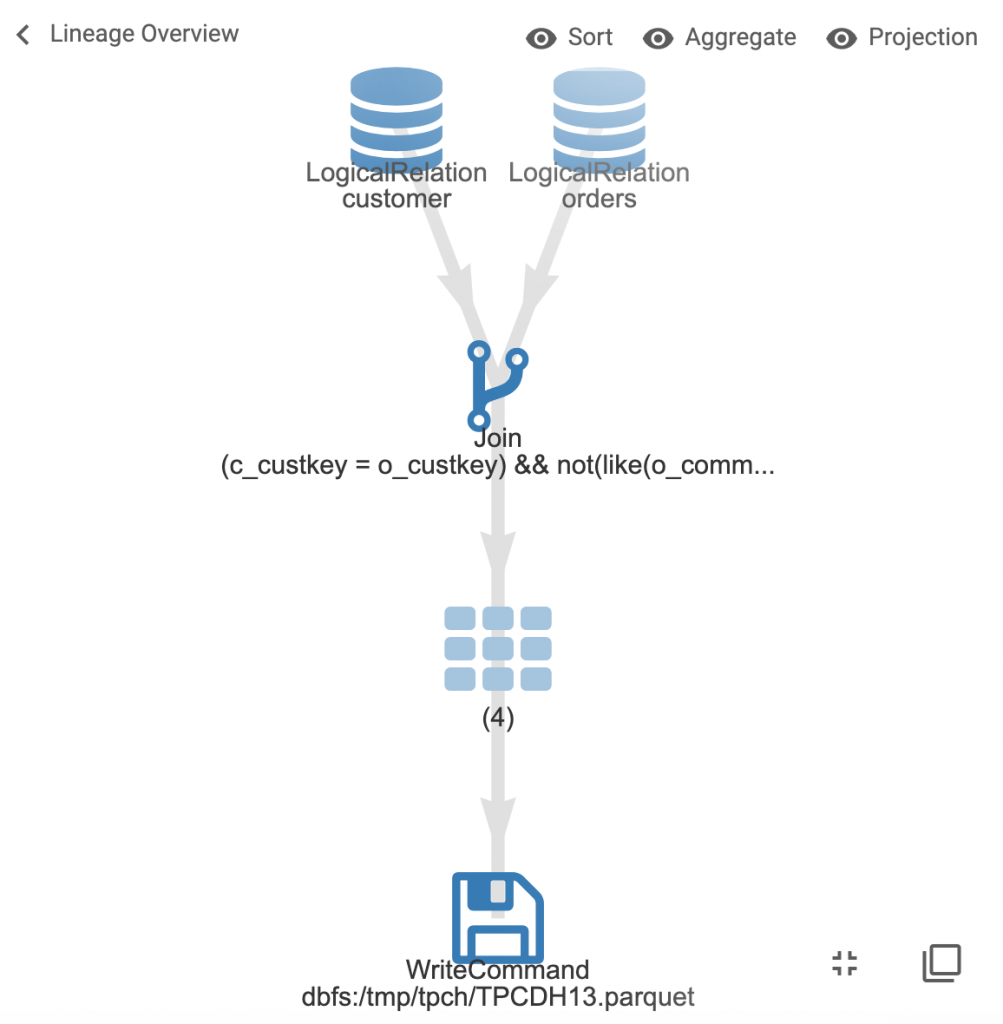
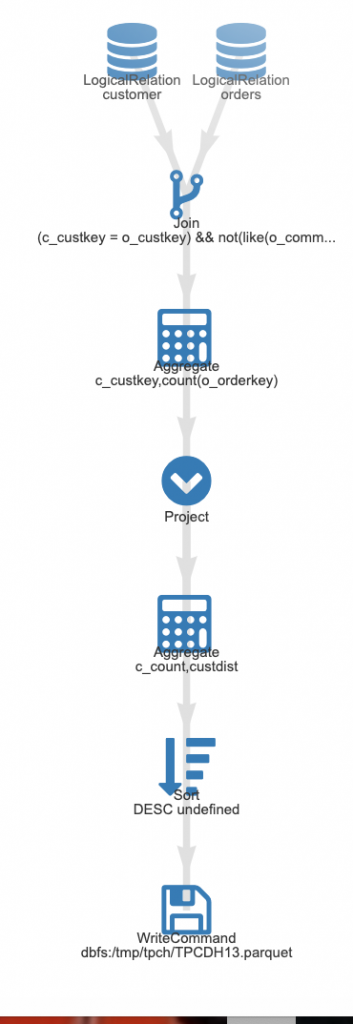
Expand further to view the detailed job graph.
Conclusion
The ability to capture detailed job lineage information with minimal changes is potentially very valuable. Please experiment with Spline and Databricks, but be aware that I have not yet performed any tests at scale. Next steps I want to look into include:
- Setting the Spline parameters at cluster level rather than in each notebook.
- Ensuring lineage gets captured when different APIs and programming languages are used.
- Testing Spline at scale, validating performance and stability.