(updated 2019-11-18 with streaming-at-scale repository link)
Apache Flink is a popular engine for distributed stream processing. In contrast to Spark Structured Streaming which processes streams as microbatches, Flink is a pure streaming engine where messages are processed one at a time.
Running Flink in a modern cloud deployment on Azure poses some challenges. Flink can be executed on YARN and could be installed on top of Azure HDInsight via custom scripts, but that is not a supported configuration, and may be an ineffective use of resources for many streaming workloads, due to the overhead of the large VM node sizes required and of the dual master nodes. Work has been done by the community to package Flink to run in Docker containers, but there is a degree of friction with Kubernetes and clearly proven best practices have not yet emerged.
While being a novice with Flink, I have started experimenting with an automated setup to run Flink in Azure Kubernetes Service, and these notes could serve as a stepping stone for further work. In this post, we are considering the case of streaming jobs that should run endlessly in a reliable manner.
Table of Contents
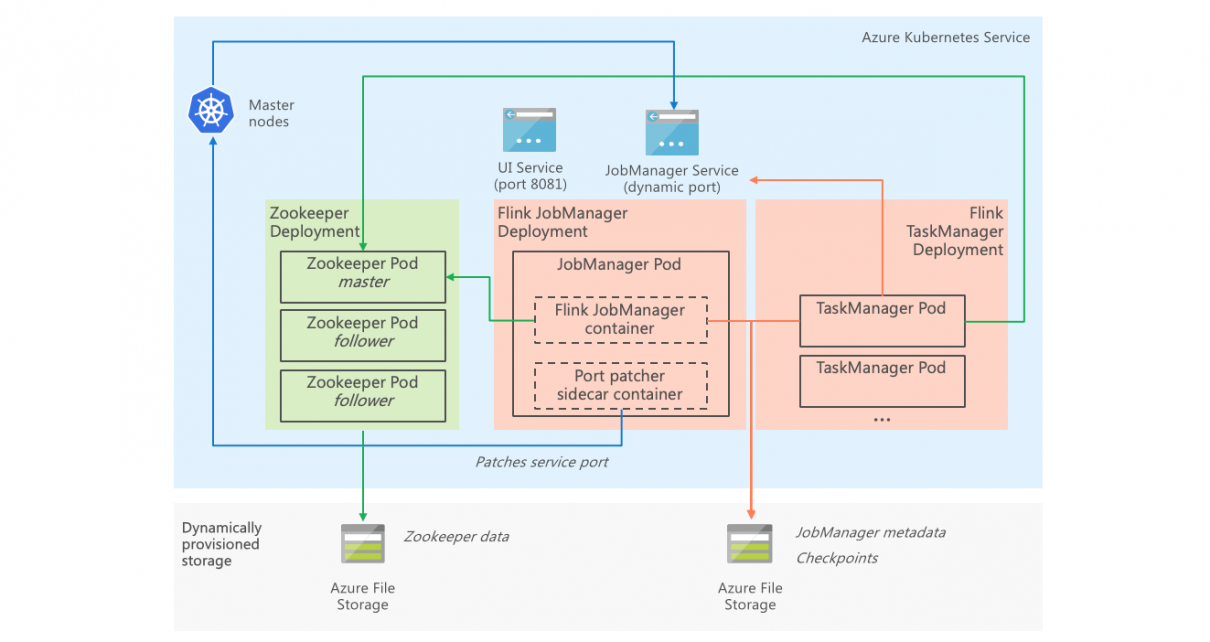
Flink deployment architecture
Flink in distributed mode runs across multiple processes, and requires at least one JobManager instance that exposes APIs and orchestrate jobs across TaskManagers, that communicate with the JobManager and run the actual stream processing code.
In Flink, consistency and availability are somewhat confusingly conflated in a single “high availability” concept. In non-HA configurations, state related to checkpoints is kept in the JobManager’s memory and is lost if the JobManager crashes. Many applications require exactly-once end-to-end stream processing guarantees. In Flink, this requires a HA configuration in order to store checkpoint metadata durably (in Zookeeper), even in cases where the degree of availability of the stream processing system is not a major concern.
Flink in Containers
Flink is developed principally for running in client-server mode, where the infrastructure a job JAR is submitted to the JobManager process and the code is then run or one or multiple TaskManager processes (depending on the job’s degree of parallelism). This approach is not desirable in a modern DevOps setup, where robust Continuous Delivery is achieved through Immutable Infrastructure, i.e. job containers should contain the entire code to perform their task, and we want to run a single fixed job per deployment. We will leverage Flink’s Standalone Job mode which allows packaging the job code with Flink and running it in a single container.
A complicating factor is that the HA implementation in Flink is based on Zookeeper and on the presence of secondary redundant JobManager instances. Zookeeper was not designed to run within modern container environments, and running spare idle JobManager instances would be wasteful.
An additional challenge is that when Flink is run in HA mode, the JobManager exposes a dynamically allocated port (this is presumably to allow running redundant JobManager on a single host, and cannot be disabled). That is exactly the opposite of what we need in a Kubernetes hosted application, where we would like to have a fixed port in order to expose a service. The TaskManager discovers the JobManager port in Zookeeper, which prevents using simple port mapping approaches.
Containerized implementation
Zookeeper
We run Zookeeper from the incubating Helm chart repository. The chart runs a ReplicaSet with 3 instances by default, and it takes a few minutes for the set to come alive. The chart automatically uses dynamically provisioned storage, making the deployment on cloud very easy.
Flink JobManager
We build a custom job container based on the standard Flink Docker container image, to which we add our compiled job JAR. We run the JobManager as a deployment with a single pod instance (given that Kubernetes will automatically redeploy the pod if it crashes).
Together with the JobManager, we run a custom sidecar container containing a small shell script. The script calls the JobManager REST API (running on fixed port 8081) to discover the JobManager RPC port, then calls the Kubernetes API to update the port exposed in the Kubernetes Service. RBAC is used to grant the sidecar container permissions to only this specific operation in the API.
As Zookeeper takes several minutes to come alive, we run an InitContainer in the pod in order to delay the JobManager container instantiation until Zookeeper is accessible.
Flink TaskManager
We run the TaskManager as a deployment with a settable number of pod instances, and the job is configured to use a parallelism level equal to the number of TaskManager instances (since we run only one job per deployment).
Sample project
A sample project contains scripts and Helm charts allowing spawning an entire Azure resource group containing Event Hubs in Kafka mode, clients producing sample events at high rate, and the Flink setup documented here running on Azure Kubernetes Service, with a very simple stream processing task (events are aggregated and counted per second on each instance). THe sample can be run from the eventhubskafka-flink-eventhubskafka directory. A sample using HDInsight Kafka is also available in the hdinsightkafka-flink-hdinsightkafka directory.
The sample project scales very well to 10,000 events per second with sub-second end-to-end latency.
Conclusion
For running stream processing workloads on Azure, I would recommend to use one of the following engines as they have SLAs and are extensively battle-tested at scale:
- Azure Stream Analytics for serverless jobs expressed in a powerful SQL syntax
- Azure Functions for serverless jobs in C#, Java, JavaScript, Python and more (Durable Functions for stateful processing)
- Spark Streaming in Azure Databricks with Delta Lake
Running Flink in Azure Kubernetes Service is a possible alternative, but requires technical expertise to build and operate a reliable solution.
References
Running Apache Flink on Kubernetes – Zalando Tech Blog
Flink Documentation – Deploy job cluster on Kubernetes