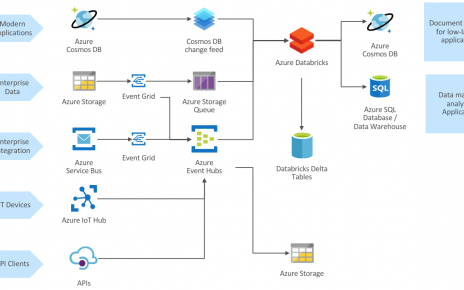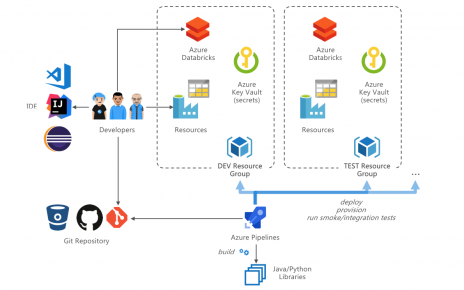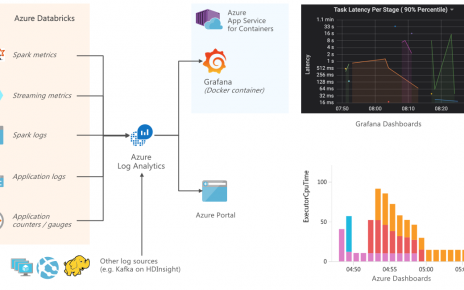
Starting out in the world of geospatial analytics can be confusing, with a profusion of libraries, data formats and complex concepts. Here are a few approaches to get started with the basics, such as importing data and running simple geometric operations. This walkthrough is demonstrated in the sample notebooks (read below to compile the GeoMesa library for Databricks in order to run the notebook successfully).
In the first part (batch processing, airport mapping sample notebook), we map airports identified with the geographical coordinates to their countries based on polygons defining the countries’ borders.
Table of Contents
Using Spark UDFs
Spark user-defined functions allow running essentially any code in parallel, so if your problem parallelises well across your dataset, you can use a simple geospatial processing library such as Shapely.
@udf("boolean")
def polygon_contains_point(polygon, point):
sh_polygon = shapely.wkt.loads(polygon)
sh_point = shapely.geometry.Point(point)
return sh_polygon.contains(sh_point)
spark.conf.set("spark.sql.crossJoin.enabled", True)
display(table("countries")
.join(table("airports"), polygon_contains_point("countries.shape",
array("airports.Longitude", "airports.Latitude")))
This results in a cross join, since the geometric contains function must be called for every pair (airport, country), so well over a million times. The command takes a relatively long time to run (36 seconds on a 3-node cluster). It is not the best approach when combining large datasets, but could be very suitable for applications such as geofencing devices with unique assigned locations (computing whether their location is within the assigned shape); in that case, we only match each location with a single shape. My colleague Sethu Raman has used that approach to run geofencing on 28,000 events per second on an 8-node cluster (the code above was adapted from his project).
When matching multiple points against each shape, a more efficient approach is to use Shapely’s vectorized operations. At this time only contains and touches have vectorised implementations. This requires us to broadcast the dataset of points, so it is limited by memory size on each worker.
import shapely.vectorized as sv
broadcastedAirports = spark.sparkContext.broadcast(airports)
@pandas_udf(ArrayType(LongType()))
def get_contained_airports(polygon):
sh_polygon = polygon.apply(wkt.loads)
ap = broadcastedAirports.value
return sh_polygon.apply(lambda g: ap.Airport_ID[sv.contains(g, x=ap.Longitude, y=ap.Latitude)].tolist())
table("countries")
.withColumn("Airport_ID", get_contained_airports("countries.geometry"))
.withColumn("Airport_ID", explode("Airport_ID"))
Naturally, we could use a more sophisticated approach to make the search run faster, such as first computing bounding boxes for countries, but let us now look at libraries that offer optimised implementations for large-scale data processing.
Geospatial libraries for Spark
Three open-source libraries offer Spark integration: Magellan, GeoSpark and GeoMesa. GitHub offers very useful statistics (in the Insights tab) to find out if a project is actively maintained.
GeoMesa appears to be the most actively maintained, and is the only one supporting the current Spark version used in Databricks (2.4.x). However, it also seems that a single highly productive developer is contributing almost all the code at the moment, which hints at what a financial analyst would call a “key person risk” for the the project’s future. A respected Italian software development company, Reply, has published a benchmark of big data spatial analytics libraries (free download) and found GeoMesa to perform best.
Using GeoMesa in Databricks
Running GeoMesa within Databricks is not straightforward:
- GeoMesa’s artefacts are published on Maven Central, but require dependencies that are only available on third-party repositories, which is cumbersome given Databricks’ library import mechanism.
- GeoMesa conflicts with an older version of the scalalogging library present in the Databricks runtime (the infamous JAR Hell problem).
I have published a Maven project that allows building an uber JAR for the GeoMesa Spark SQL that works on Databricks. This allows running geospatial operations such as spatial joining using fluent operators:
countries.as("countries")
.join(airports.as("airports"), st_contains($"countries.shape", $"airports.location"))
The sample notebook shows how to import geospatial open datasets of country shapes and airport locations and map them to each other. The join runs in slightly under 10 seconds on the same cluster.
Structured Stream processing
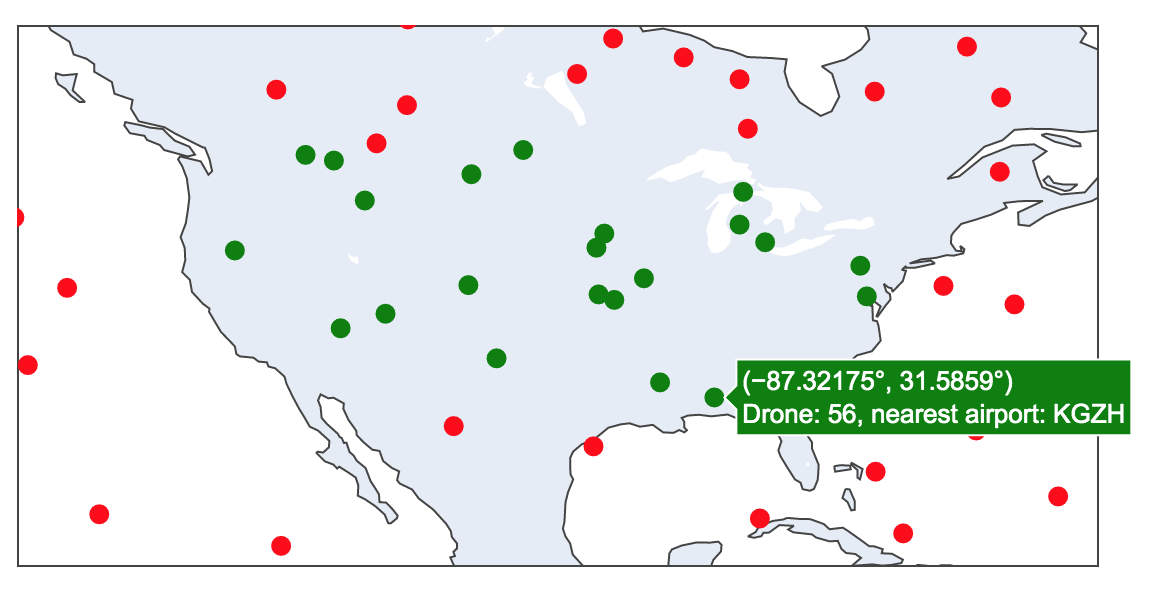
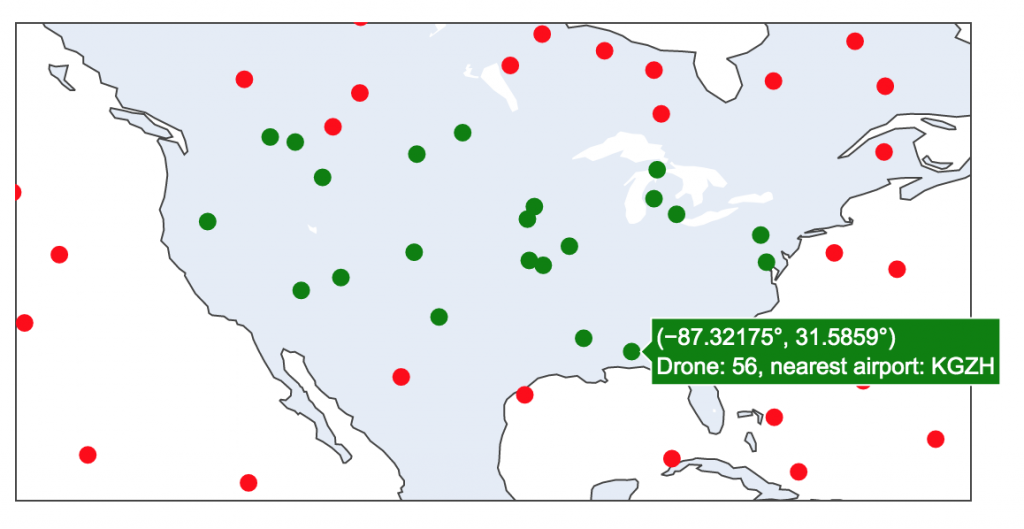
In the second notebook (drone tracking sample notebook), we use Spark Structured Streaming to apply geofencing and map the nearest airport to a stream of events in near-real time. The notebook includes interactive data visualisation.
Conclusion
GeoMesa appears to be a powerful library, and it’s worth exploring its various modules and testing its performance at scale. The GeoMesa Spark SQL module appears to perform well, but I haven’t had success with the Spark FileSystem module (allowing to directly import various file formats) as it expects a Hadoop system, which Databricks does not contain.