A simple way to unit test notebooks is to write the logic in a notebook that accepts parameterized inputs, and a separate test notebook that contains assertions.
The sample project https://github.com/algattik/databricks-unit-tests/ contains two demonstration notebooks:
- The normalize_orders notebook processes a list of Orders and a list of OrderDetails into a joined list, taking into account missing items and performing an aggregate calculation.
- The test_normalize_orders notebook calls the normalize_orders with fixed inputs and performs assertions on the output.
These are Python notebooks, but you can use the same logic in Scala or R. For SQL notebooks, parameters are not allowed, but you could create views to have the same SQL code work in test and production.
The normalize_orders notebook takes parameters as input. Note that Databricks notebooks can only have parameters of string type.
dbutils.widgets.text("orders", defaultValue="dbfs:/test-data/orders.txt", label="Source orders path")
dbutils.widgets.text("orderDetails", defaultValue="dbfs:/test-data/orderDetails.txt", label="Source order details path")
dbutils.widgets.text("output", defaultValue="test_output", label="Output order details spark table name")
Setting the default values to test datasets help when iterating on the notebook, but in production you will probably pass remote storage URLs, such as abfss://filesystem@account.dfs.core.windows.net/path.
After processing, the notebook writes to a table. Note the write mode used: whenever possible, resist the temptation to append to outputs, always overwrite to avoid risk of duplicating outputs
upon retry of failed jobs.
(orders_full
.write
.mode("overwrite")
.saveAsTable(dbutils.widgets.get("output"))
)
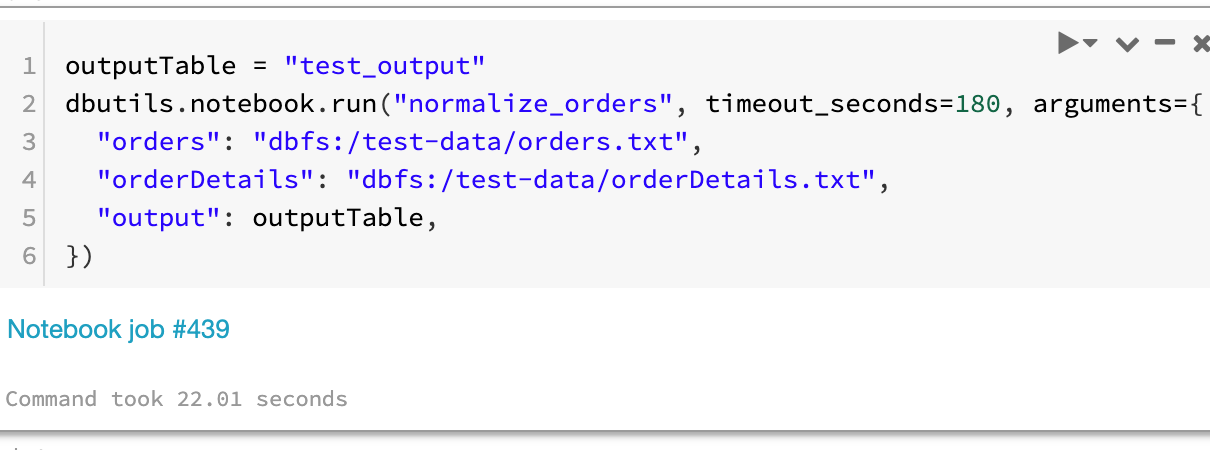
The test_normalize_orders notebook writes input data to a DBFS location, then runs the normalize_orders notebook
dbutils.fs.put("dbfs:/test-data/orders.txt", orders, overwrite=True)
dbutils.fs.put("dbfs:/test-data/orderDetails.txt", orderDetails, overwrite=True)
outputTable = "test_output"
dbutils.notebook.run("normalize_orders", timeout_seconds=180, arguments={
"orders": "dbfs:/test-data/orders.txt",
"orderDetails": "dbfs:/test-data/orderDetails.txt",
"output": outputTable,
})
The test_normalize_orders notebook then reads the output produced by the normalized_orders notebook. Note that we need to refresh the table metadata between two reads of a table that has been overwritten in the meantime. This will avoid errors when running this cell multiple times while developing the test_normalize_orders notebook.
spark.catalog.refreshTable(outputTable)
output = table(outputTable)
Should you use this pattern to test your Spark logic? Notebooks are clearly not a good artifact for software engineering. Joel Grus of the Allen Institute for Artificial Intelligence even dared to present an entire talk on this topic at JupyterCon!
Notebooks are a great environment for prototyping code, but for maintainable artifacts, you should write your core logic into modules (Scala JARs or Python wheel), and run them directly as Databricks jobs. Short notebooks can still have a place to manage glue logic such as inputs and outputs, as well as dashboards and visualizations. Unit tests then belong in the build of your module, using standard testing libraries such as ScalaTest or pytest.