You can use Terraform as a single source of configuration for multiple pipelines. This enables you to centralize configuration across your project, such as your naming strategy for resources.
When running terraform apply, the Terraform state (usually a blob in Azure Storage) contains the values of your defined Terraform outputs. In your output.tf:
output "service_url" {
description = "Application URL"
value = module.application.service_url
}
output "iothub_shared_access_policy" {
description = "Iot Hub shared access policy"
value = module.iothub.shared_access_policy
sensitive = true
}The Azure Pipelines Terraform task can make these outputs available in a file. You will typically need those outputs in other pipelines. You could manage the Terraform output file as an artifact, but that is cumbersome and raises security concerns.
Table of Contents
Using outputs in other pipelines
For another pipeline to use Terraform outputs, various possibilities exist. These are detailed in the following sections.
Exporting Terraform outputs to a variable group
One option is to use the Azure DevOps provider for Terraform (azuredevops_variable_group resource) to populate data directly into variable groups. However, that provider is still in preview and requires setting up personal access tokens. Here is an alternative approach using scripting.
Create a variable group named my-vg-name. Add any dummy variable in the variable group when creating it (it will be overwritten anyway). In the Security tab of the variable group, grant Administrator
permissions to the Build service User (e.g. MyProject Build Service (MyOrganization).
Add the following task to your Terraform pipeline (after the Terraform apply step).
- bash: |
set -euo pipefail
# Build base URL for REST API call variable groups endpoint
# escape URI characters in SYSTEM_TEAMPROJECT e.g. " " => "%20"
TEAMPROJECT_ESCAPED=$(prj="$SYSTEM_TEAMPROJECT" jq -n -r 'env.prj | @uri')
URL=$SYSTEM_COLLECTIONURI$TEAMPROJECT_ESCAPED/_apis/distributedtask/variablegroups
# Retrieve Variable Group ID from Variable Group Name
VG_INFO=$(curl -u "$USER" "$URL?groupName=$VG_NAME&api-version=5.1-preview.1")
if ! VG_ID=$(jq '.value[0].id' <<< "$VG_INFO"); then
echo "Failed to retrieve Variable Group: $VG_NAME"
echo "$VG_INFO"
exit 1
fi
# PUT Terraform variables to variable group
terraform output -json \
| VG_NAME="$VG_NAME" VG_DESC="$VG_DESC" jq \
'{ name: env.VG_NAME,
description: env.VG_DESC,
variables: with_entries(.value.isSecret=.value.sensitive) }' \
| curl -fu "$USER" "$URL/$VG_ID?api-version=5.1-preview.1" --data @- -H Content-type:application/json -X PUT > /dev/null
displayName: Store Terraform outputs in variable group
workingDirectory: 'my-terraform-directory'
env:
USER: token:$(System.AccessToken)
VG_NAME: "my-vg-name"
VG_DESC: "Terraform outputs (automatically generated from Terraform pipeline, do not edit!)"After running the pipeline, the variable group will be automatically populated.
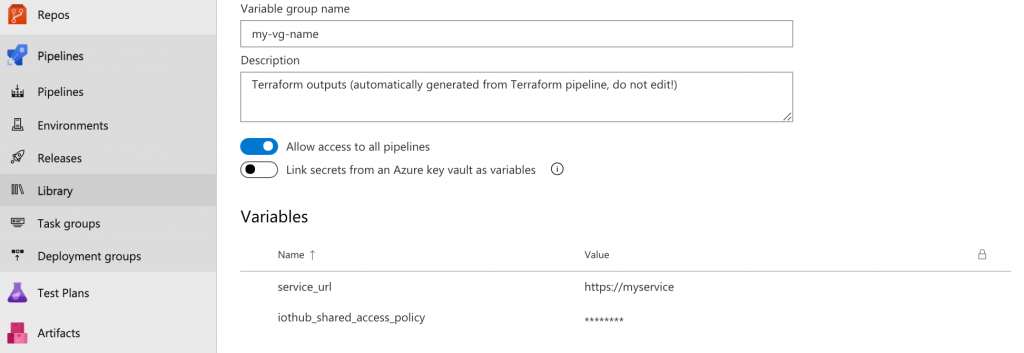
Other pipelines can access the variables by referencing the variable group:
variables:
- group: my-vg-nameExporting Terraform outputs to an Azure Key Vault
You could adapt the approach above to export outputs to an Azure Key Vault instead, and use the secrets in your pipeline or link your secrets to a Variable Group.
In that case, rather than using outputs, you might prefer populating secrets directly using azurerm_key_vault_secret Terraform resource.
An advantage of using Azure Key Vault is that you can import data directly into your application as configuration in .NET Core or Java (Spring Boot). SDKs are also available for other languages. That can simplify the developer experience.
Reading outputs from Terraform state
An alternative approach, not to use a variable group, is to create a task that reads all the outputs from the Terraform state and outputs them as pipeline variables. While this prevents duplicating the data in a Variable
Group, it has the downsides of additional coupling, and the performance impact of requiring to run terraform init and terraform output at every pipeline run.
You can use the output command of Charles Zipp’s marketplace extension for Terraform for this.
If you do not wish to use community extensions, here is an equivalent script:
jobs:
- job: Terraform_outputs
steps:
- bash: |
set -euo pipefail
echo "Setting job variables from Terraform outputs:"
terraform output -json | jq -r '
. as $in
| keys[]
| ($in[.].value | tostring | gsub("\\"; "\\") | gsub("\n"; "\n")) as $value
| ($in[.].sensitive | tostring) as $sensitive
| [
"- " + . + ": " + if $in[.].sensitive then "(sensitive)" else $value end, # output name to console
"##vso[task.setvariable variable=" + . + ";isSecret=" + $sensitive + "]" + $value, # set as ADO task variable
"##vso[task.setvariable variable=" + . + ";isOutput=true;isSecret=" + $sensitive + "]" + $value # also set as ADO job variable
]
| .[]'
name: Outputs
displayName: Read Terraform outputs
workingDirectory: 'my-terraform-directory'You can then use any Terraform output in the same job:
- bash: echo "Service URL: $(Outputs.service_url)"Or in another job:
- job: Terraform
dependsOn:
- Terraform_outputs
variables:
SERVICE_URL: $[ dependencies.Terraform_shared_outputs.outputs['service_url'] ]
steps:
- bash: echo "Service URL: $(SERVICE_URL)"Or even in another stage.
In GitHub Actions
To read Terraform outputs in a GitHub actions, assuming your state is stored in an Azure Storage blob, you can use this code. Setting variables in $GITHUB_ENV makes them available for subsequent steps in the same job.
steps:
- uses: azure/login@v1
with:
creds: ${{ secrets.AZURE_CREDENTIALS }}
- name: "Read terraform outputs"
run: |
terraform init
terraform output -json \
| jq -r '. as $in | keys[] | ($in[.].value | tostring | gsub("\\"; "\\") | gsub("\n"; "\n")) as $value | . + "=" + $value' \
>> $GITHUB_ENV