Sometimes you need to download a collection of JAR files, as well as their dependencies, for example to provide to a PySpark job. One way for this is to use Maven. Running this: Will download the specified JARs and their transitive dependencies into the target folder:
Snippets
Resolving Azure Function Key Vault secrets in local development
When using the @Microsoft.KeyVault(SecretUri=…) syntax for App Service configuration in Azure Functions, these settings are not resolved when debugging locally. The following script resolves such secret references to their values. After verifying the output file local.settings.tmp, overwrite local.settings.json with it. cat local.settings.json \ | jq -r ‘.Values[]|select(startswith(“@”))|match(“SecretUri=(.*)\\\\)”).captures[0].string’ \ | sort -u | xargs -n1 az […]
Using Azure AD with the Azure Databricks API
In the past, the Azure Databricks API has required a Personal Access Token (PAT), which must be manually generated in the UI. This complicates DevOps scenarios. A new feature in preview allows using Azure AD to authenticate with the API. You can use it in two ways: Use Azure AD to authenticate each Azure Databricks […]
Updating Variable Groups from an Azure DevOps pipeline
We often need a permanent data store across Azure DevOps pipelines, for scenarios such as: Passing variables from one stage to the next in a multi-stage release pipeline. Any variables defined in a task are only propagated to tasks in the same stage. Storing state between pipeline runs, for example a blue/green deployment release pipeline […]
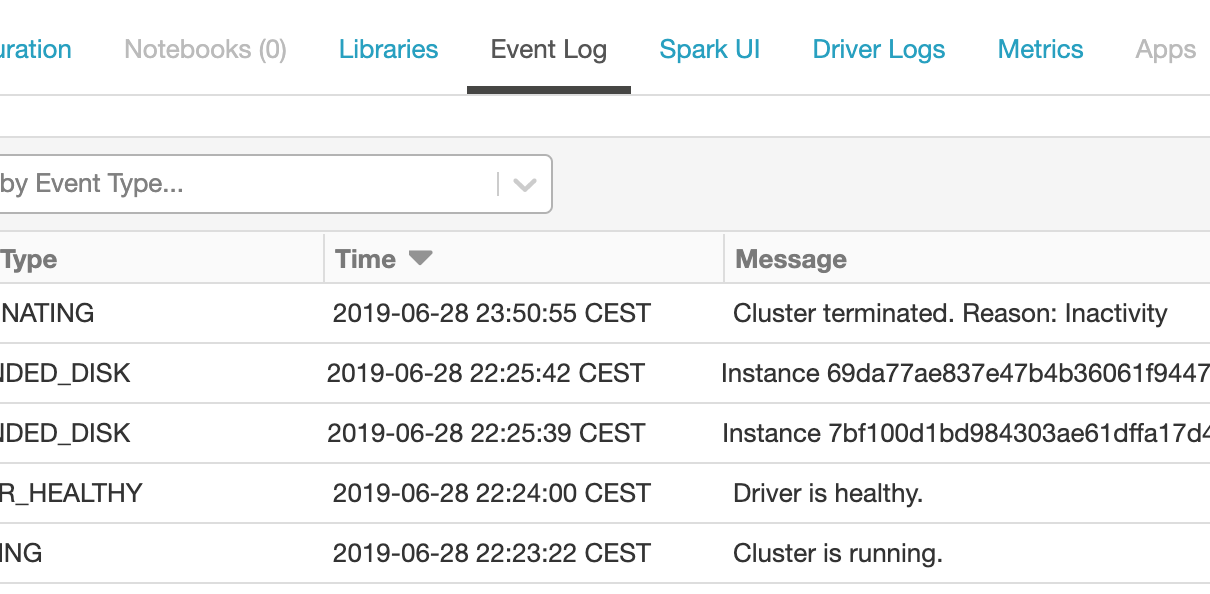
Exporting Databricks cluster events to Log Analytics
For running analytics and alerts off Azure Databricks events, best practice is to process cluster logs using cluster log delivery and set up the Spark monitoring library to ingest events into Azure Log Analytics. However, in some cases it might be sufficient to set up a lightweight event ingestion pipeline that pushes events from the […]
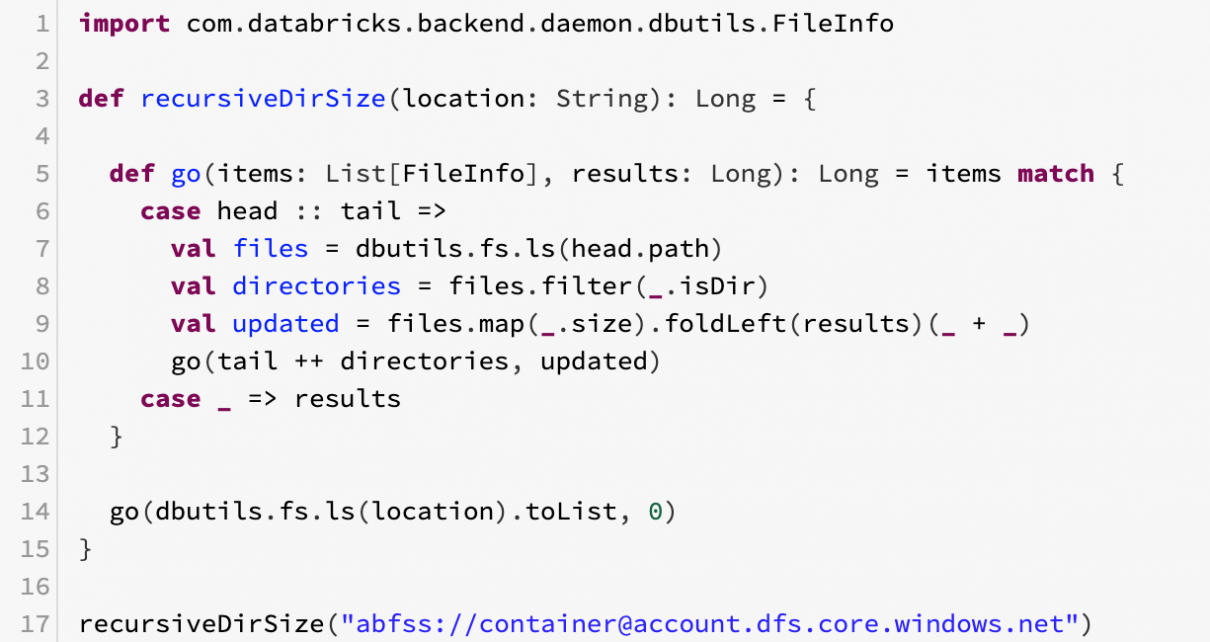
Computing total storage size of a folder in Azure Data Lake Storage Gen2
Until Azure Storage Explorer implements the Selection Statistics feature for ADLS Gen2, here is a code snippet for Databricks to recursively compute the storage size used by ADLS Gen2 accounts (or any other type of storage). The code is quite inefficient as it runs in a single thread in the driver, so if you have […]

Running Azure Databricks notebooks in parallel
You can run multiple Azure Databricks notebooks in parallel by using the dbutils library. Here is a snippet based on the sample code from the Azure Databricks documentation on running notebooks concurrently and on Notebook workflows as well as code from code by my colleague Abhishek Mehra, with additional parameterization, retry logic and error handling. Note […]
Accessing Azure Data Lake Storage Gen2 from clients
Azure Data Lake Storage Gen2 can be easily accessed from the command line or from applications on HDInsight or Databricks. If you are developing an application on another platform, you can use the driver provided in Hadoop as of release 3.2.0 in the command line or as a Java SDK. Using the Hadoop File System […]