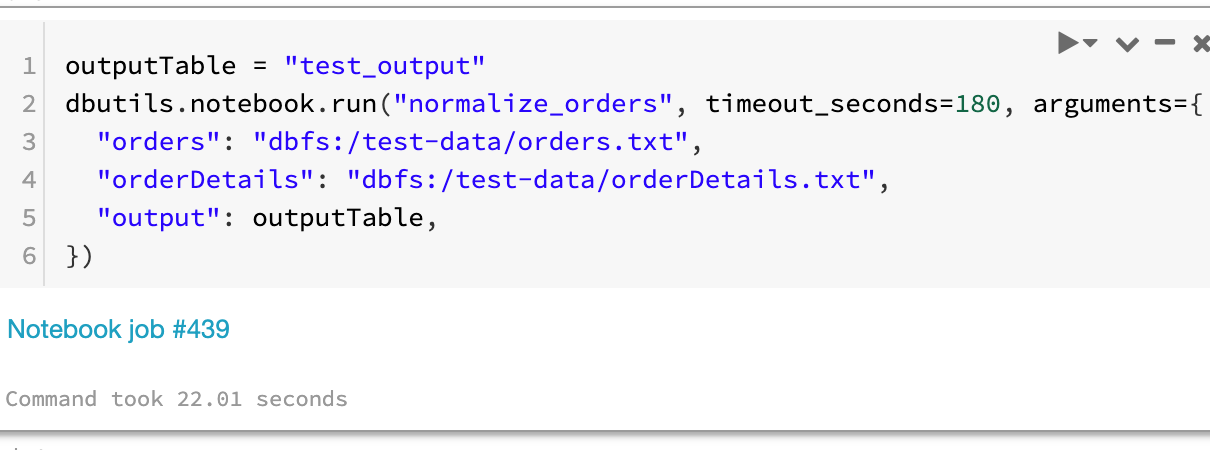
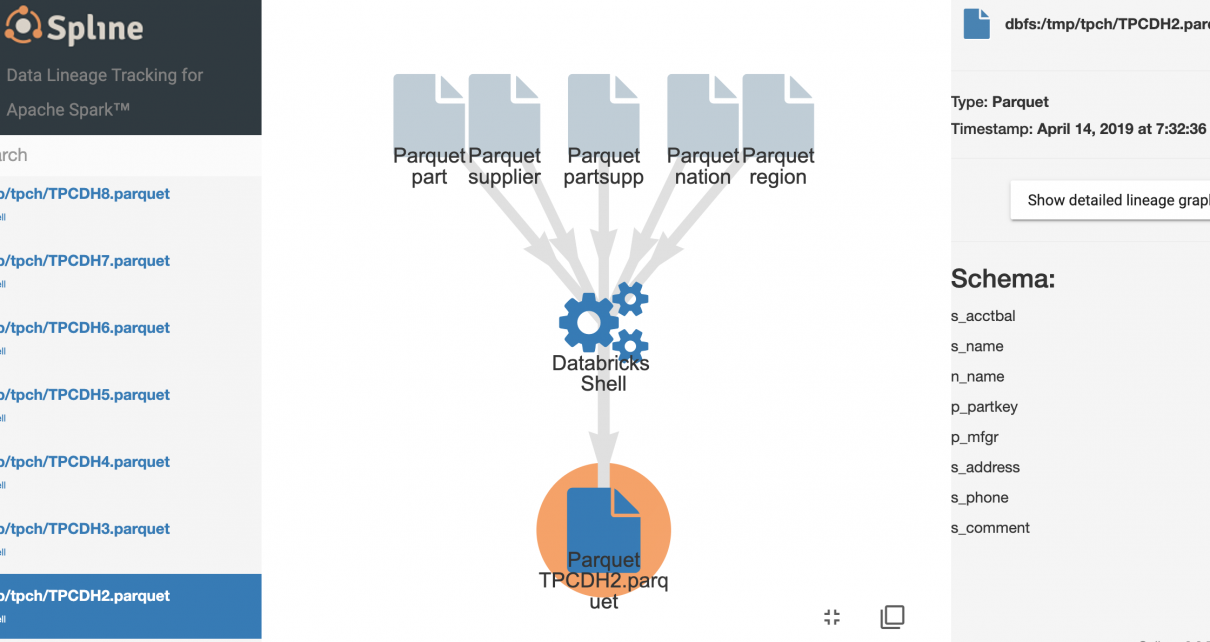
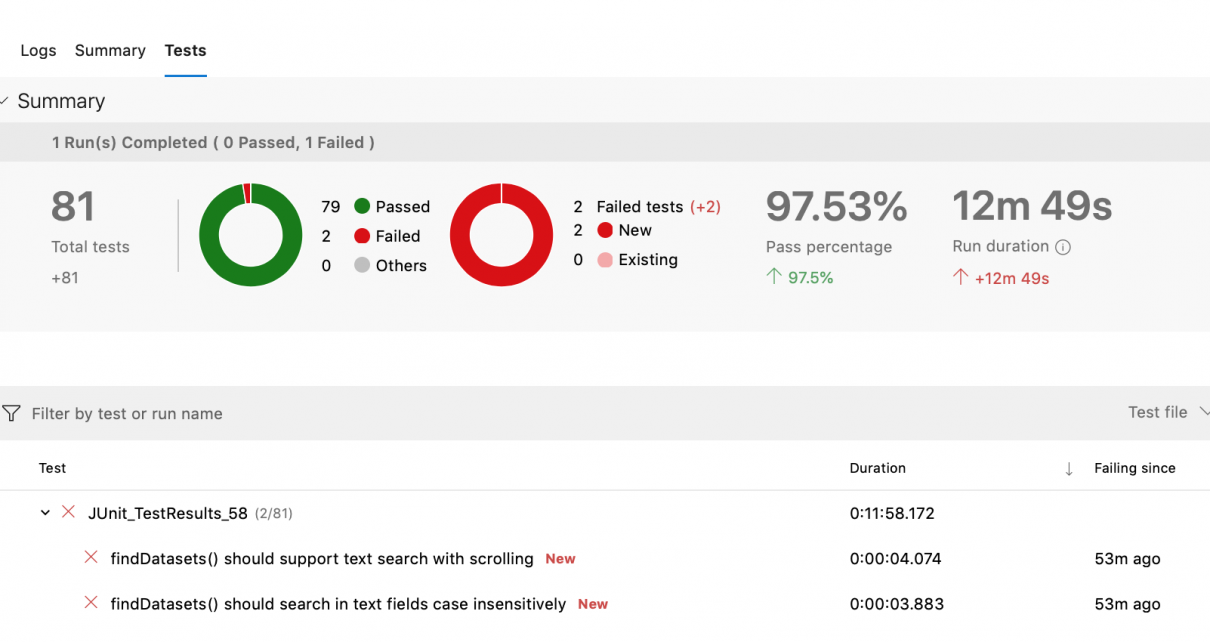
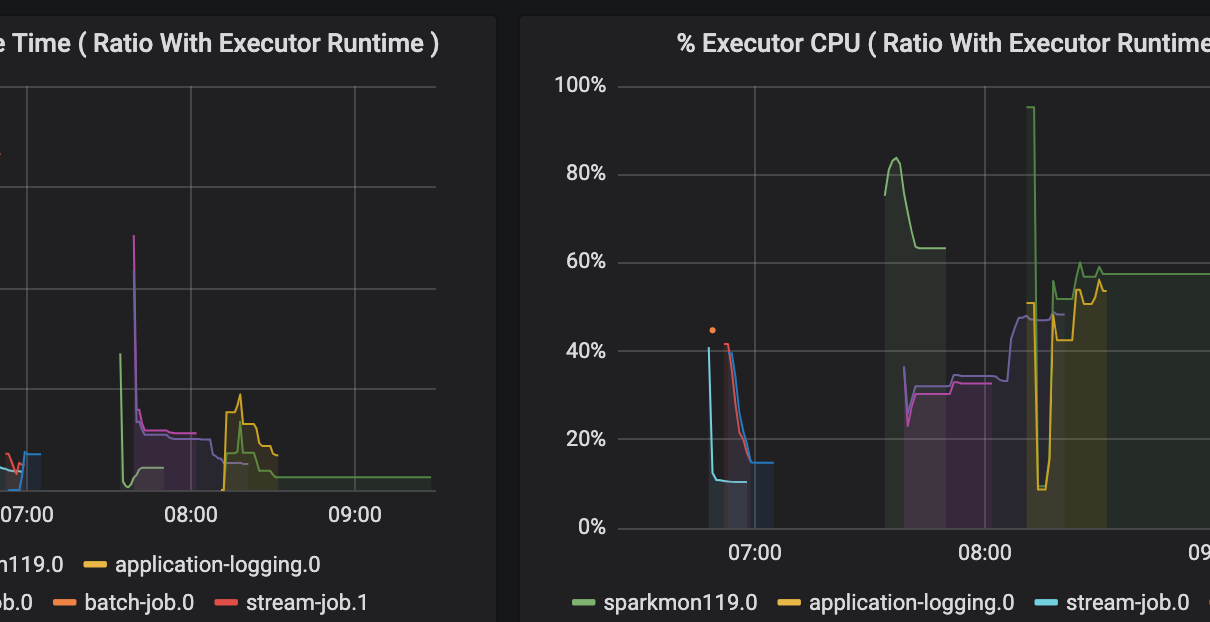
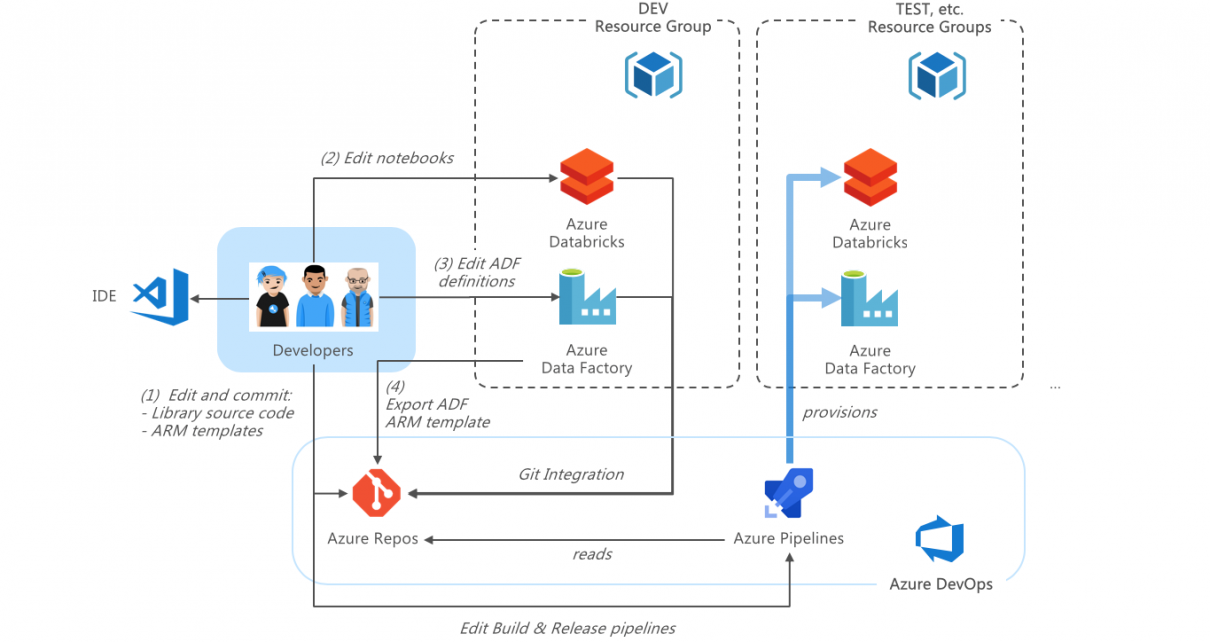
You can use Terraform as a single source of configuration for multiple pipelines. This enables you to centralize configuration across your project, such as your naming strategy for resources. When running terraform apply, the Terraform state (usually a blob in Azure Storage) contains the values of your defined Terraform outputs. In your output.tf: The Azure […]