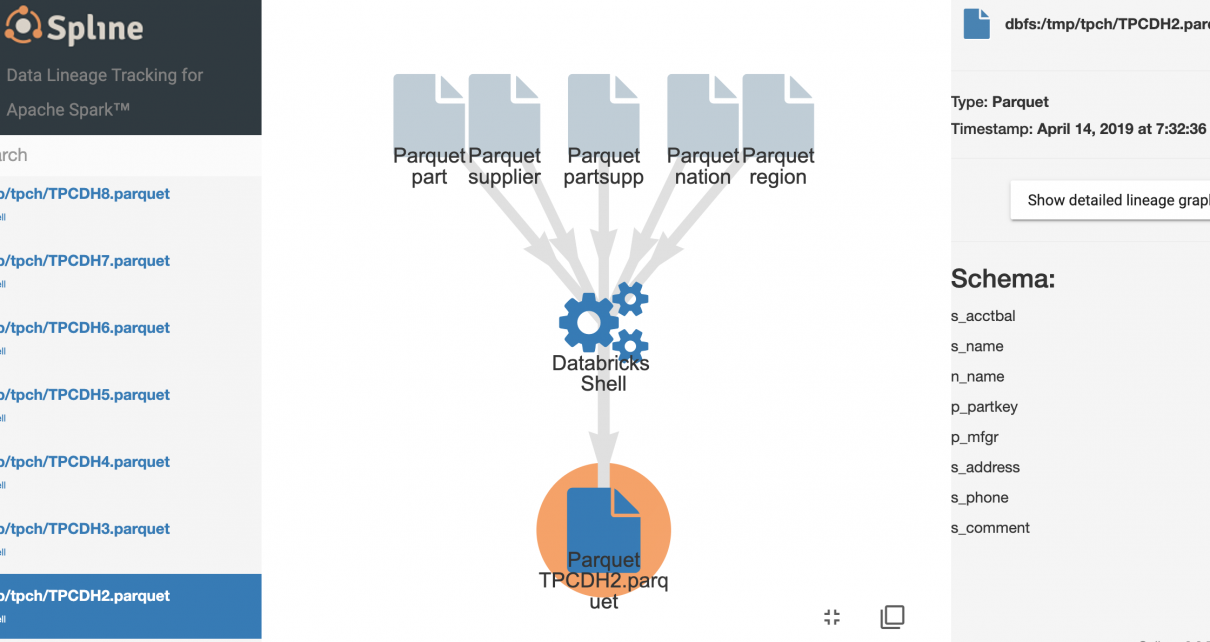
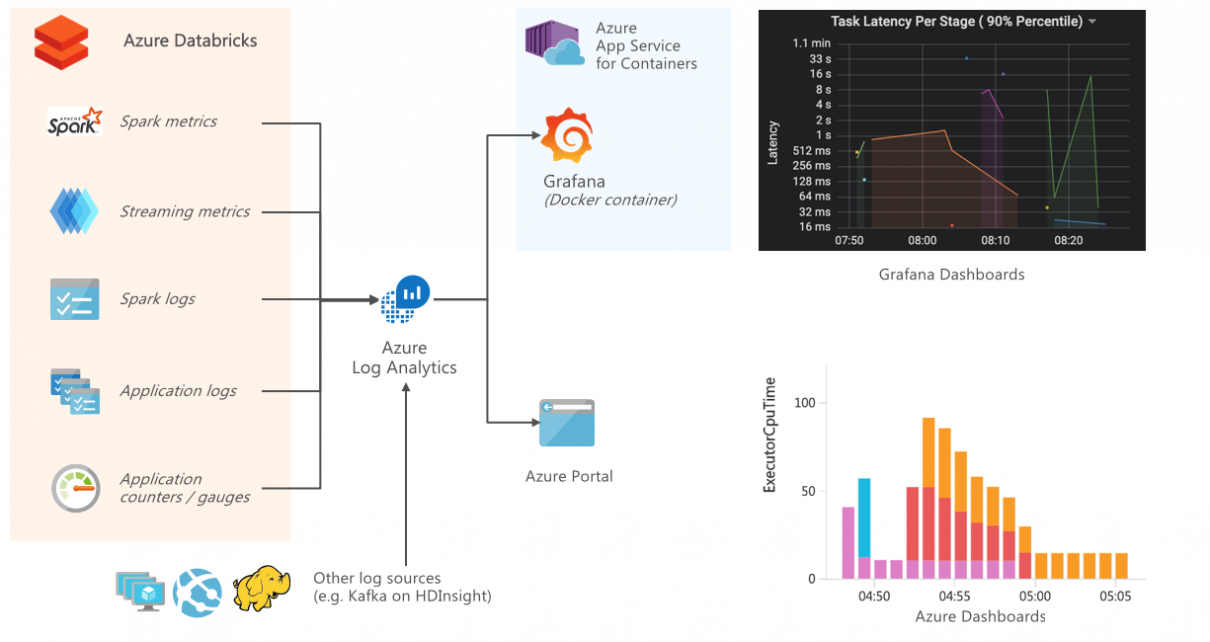
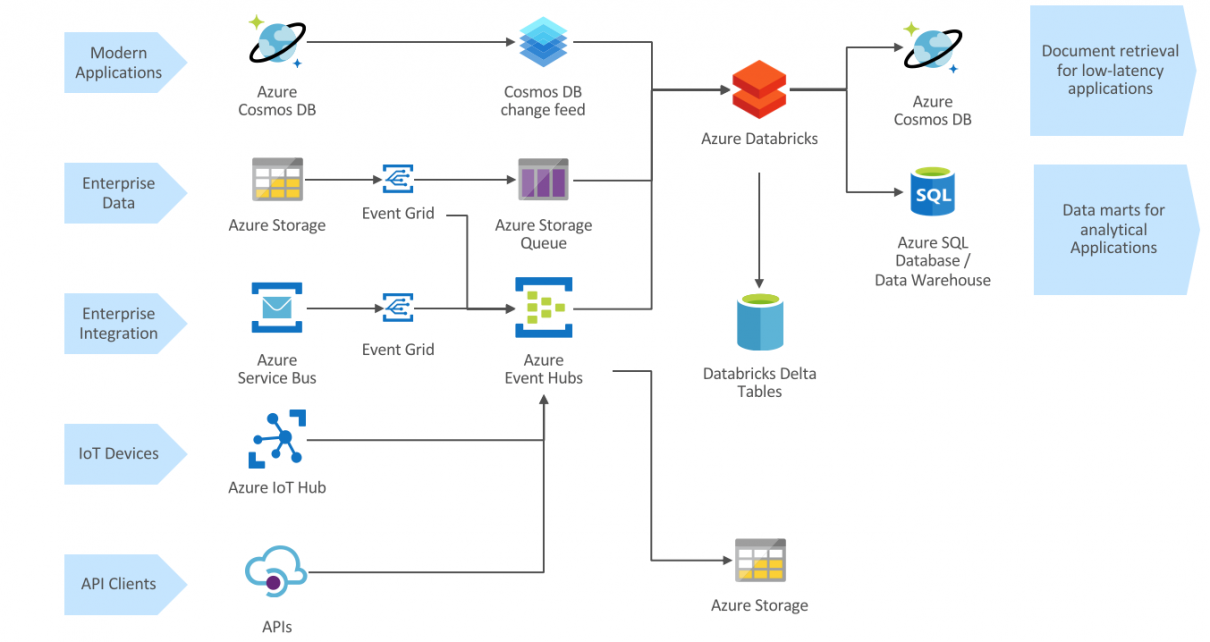
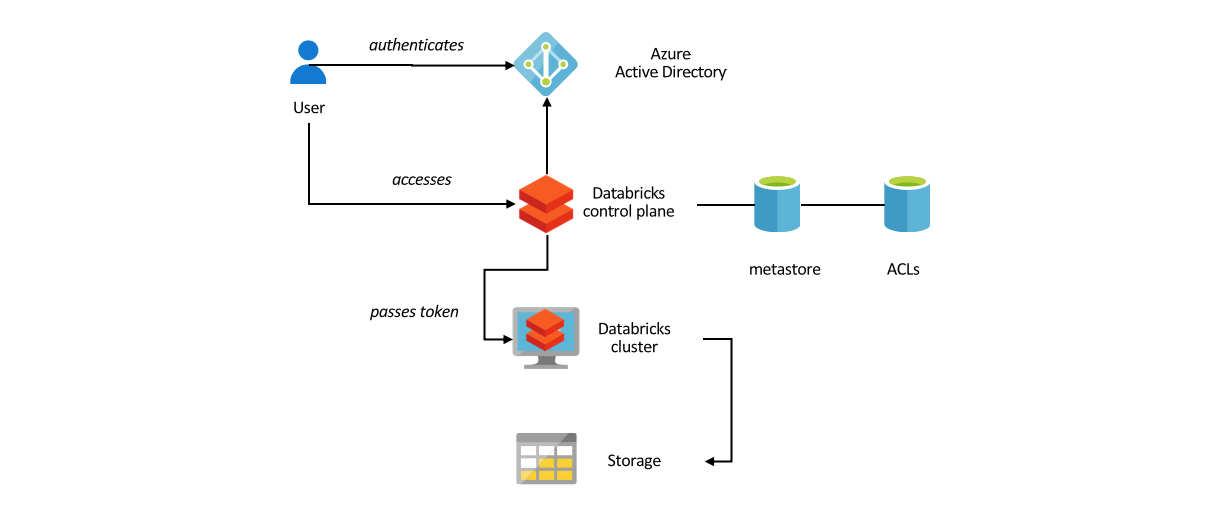
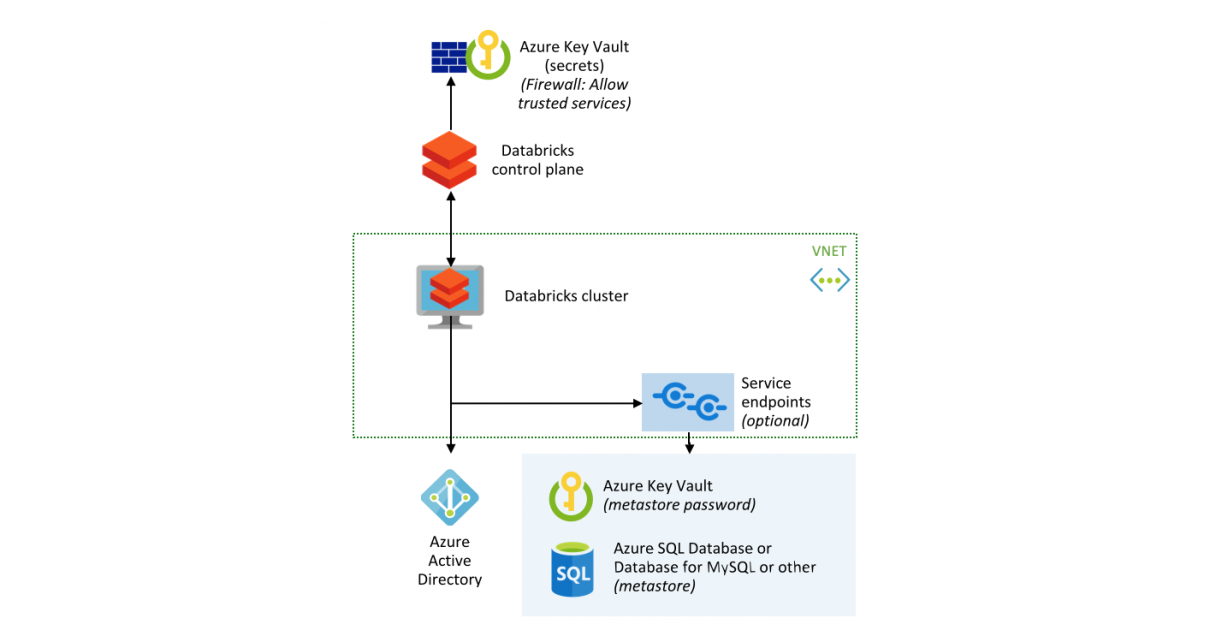
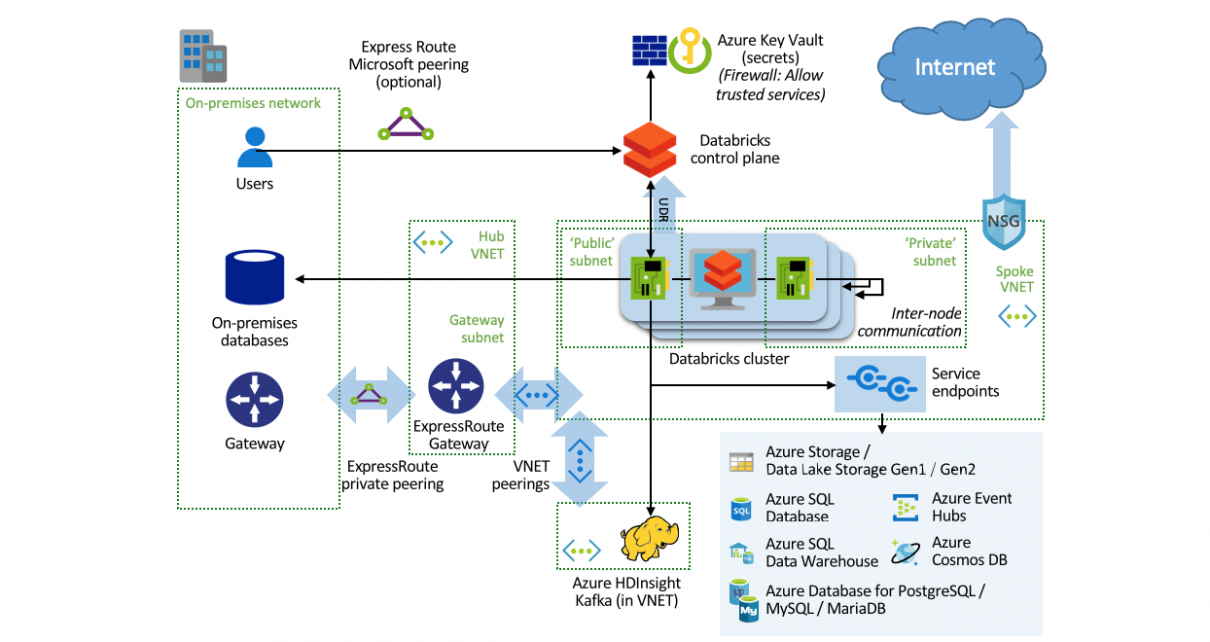
The Spline open-source project can be used to automatically capture data lineage information from Spark jobs, and provide an interactive GUI to search and visualize data lineage information. We provide an Azure DevOps template project that automates the deployment of an end-to-end demo project in your environment, using Azure Databricks, Cosmos DB and Azure App […]