See Part 1, Using Azure AD With The Azure Databricks API, for a background on the Azure AD authentication mechanism for Databricks. Here we show how to bootstrap the provisioning of an Azure Databricks workspace and generate a PAT Token that can be used by downstream applications. Create a script generate-pat-token.sh with the following content. […]
Tag: databricks
Using Azure AD with the Azure Databricks API
In the past, the Azure Databricks API has required a Personal Access Token (PAT), which must be manually generated in the UI. This complicates DevOps scenarios. A new feature in preview allows using Azure AD to authenticate with the API. You can use it in two ways: Use Azure AD to authenticate each Azure Databricks […]
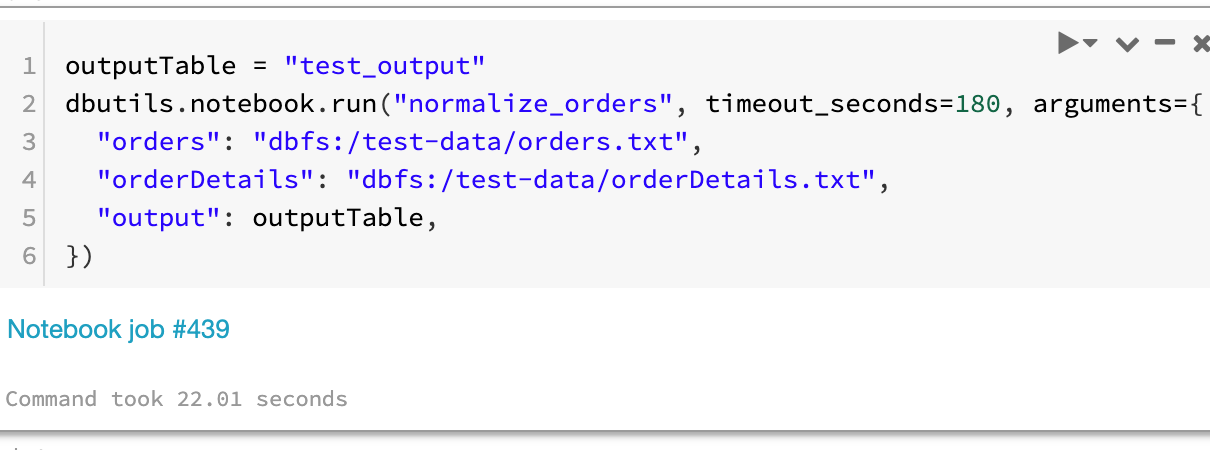
Unit testing Databricks notebooks
A simple way to unit test notebooks is to write the logic in a notebook that accepts parameterized inputs, and a separate test notebook that contains assertions. The sample project https://github.com/algattik/databricks-unit-tests/ contains two demonstration notebooks: The normalize_orders notebook processes a list of Orders and a list of OrderDetails into a joined list, taking into account […]
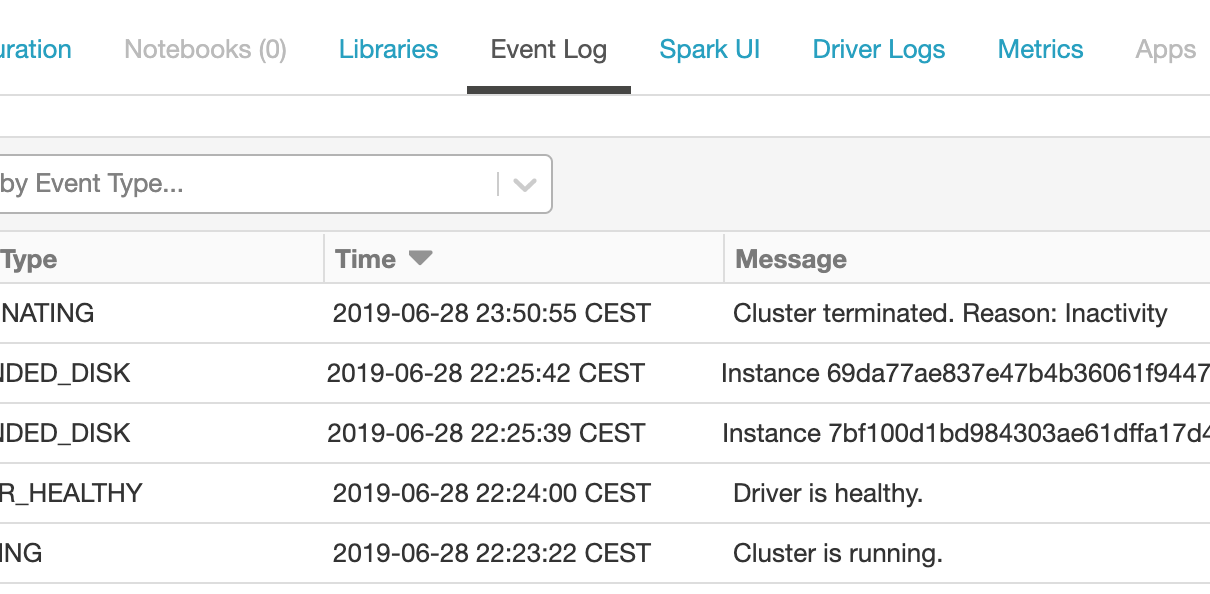
Exporting Databricks cluster events to Log Analytics
For running analytics and alerts off Azure Databricks events, best practice is to process cluster logs using cluster log delivery and set up the Spark monitoring library to ingest events into Azure Log Analytics. However, in some cases it might be sufficient to set up a lightweight event ingestion pipeline that pushes events from the […]
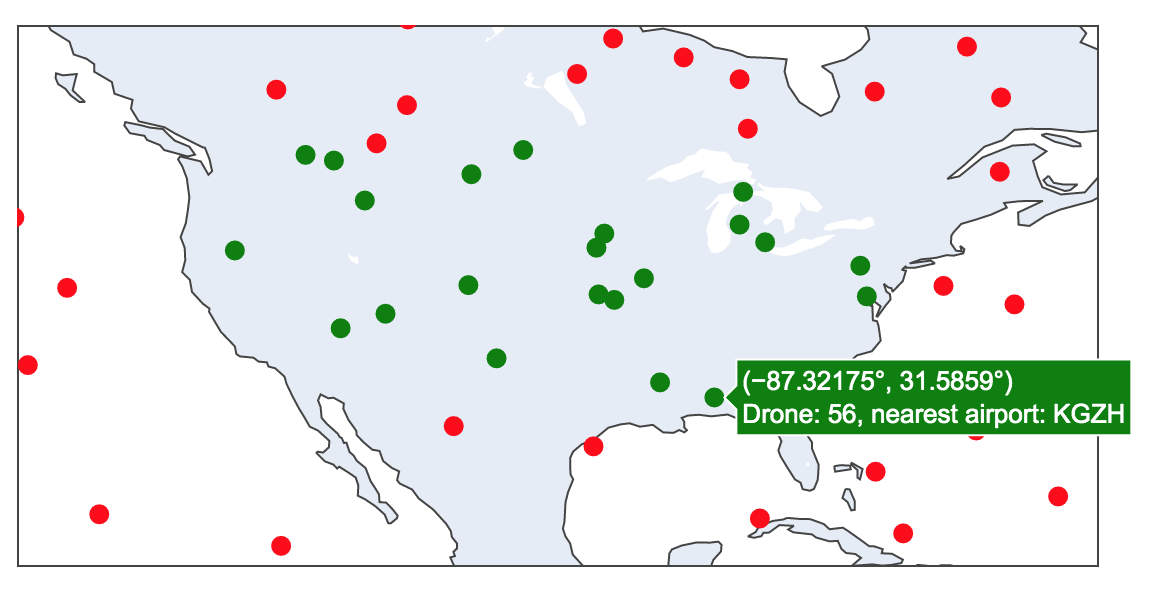
Geospatial Analytics in Databricks with Python and GeoMesa
Starting out in the world of geospatial analytics can be confusing, with a profusion of libraries, data formats and complex concepts. Here are a few approaches to get started with the basics, such as importing data and running simple geometric operations. This walkthrough is demonstrated in the sample notebooks (read below to compile the GeoMesa […]
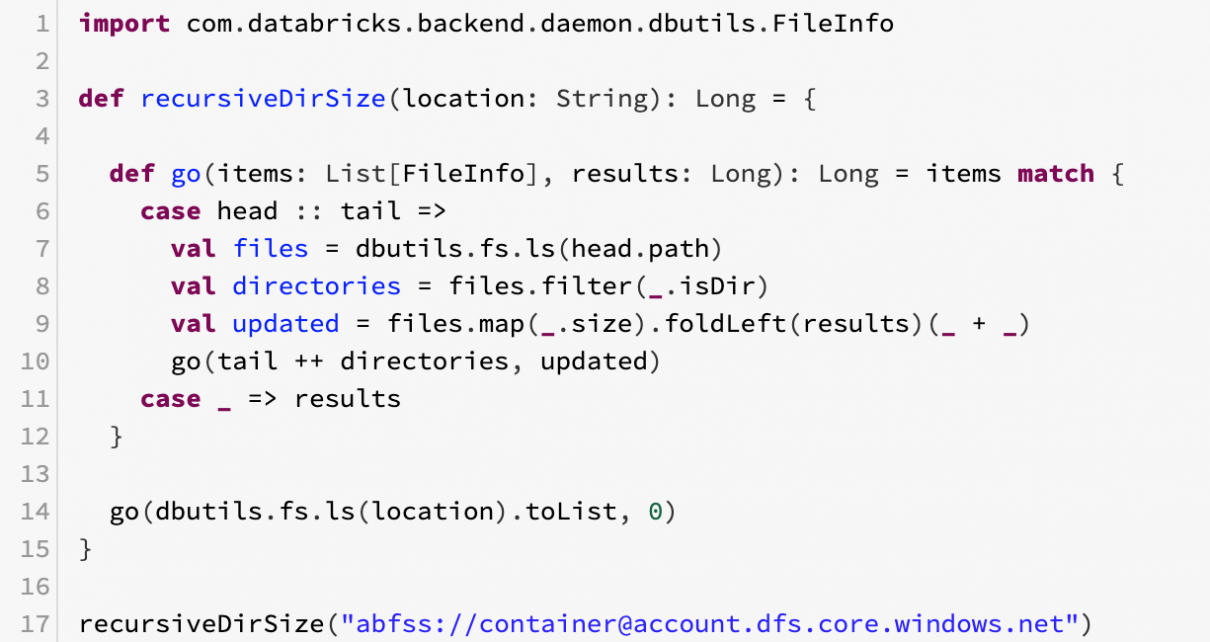
Computing total storage size of a folder in Azure Data Lake Storage Gen2
Until Azure Storage Explorer implements the Selection Statistics feature for ADLS Gen2, here is a code snippet for Databricks to recursively compute the storage size used by ADLS Gen2 accounts (or any other type of storage). The code is quite inefficient as it runs in a single thread in the driver, so if you have […]

Using the TensorFlow Object Detection API on Azure Databricks
The easiest way to train an Object Detection model is to use the Azure Custom Vision cognitive service. That said, the Custom Vision service is optimized to quickly recognize major differences between images, which means it can be trained with small datasets, but is not optimized for detecting subtle differences in images (for example, detecting […]
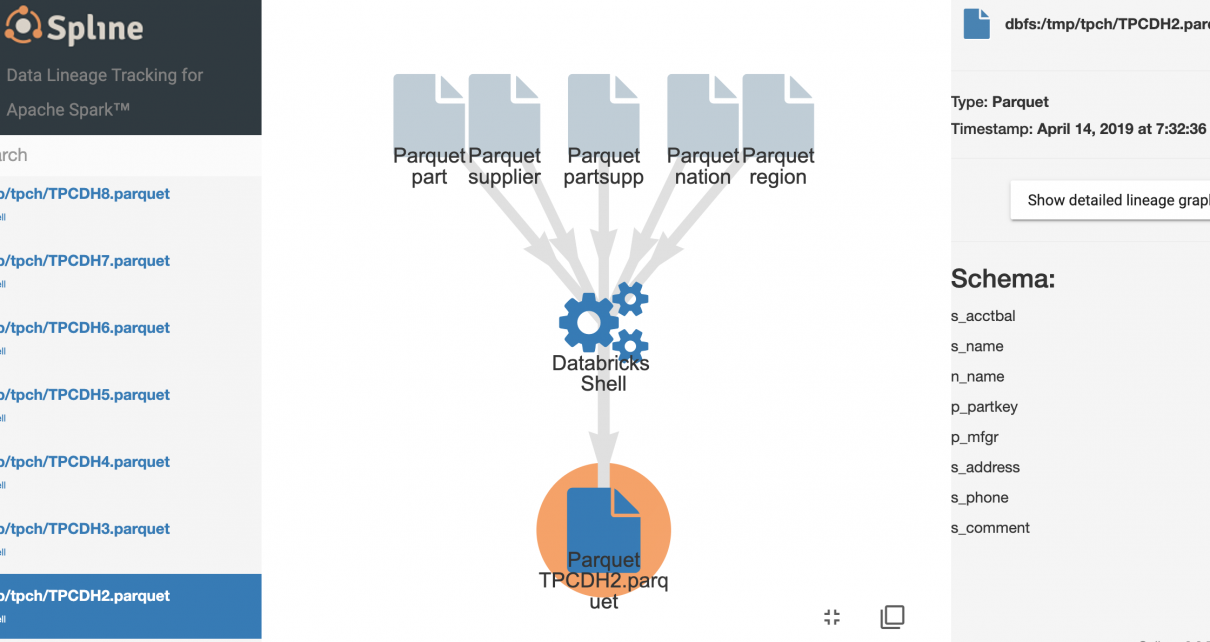
Data Lineage in Azure Databricks with Spline
The Spline open-source project can be used to automatically capture data lineage information from Spark jobs, and provide an interactive GUI to search and visualize data lineage information. We provide an Azure DevOps template project that automates the deployment of an end-to-end demo project in your environment, using Azure Databricks, Cosmos DB and Azure App […]
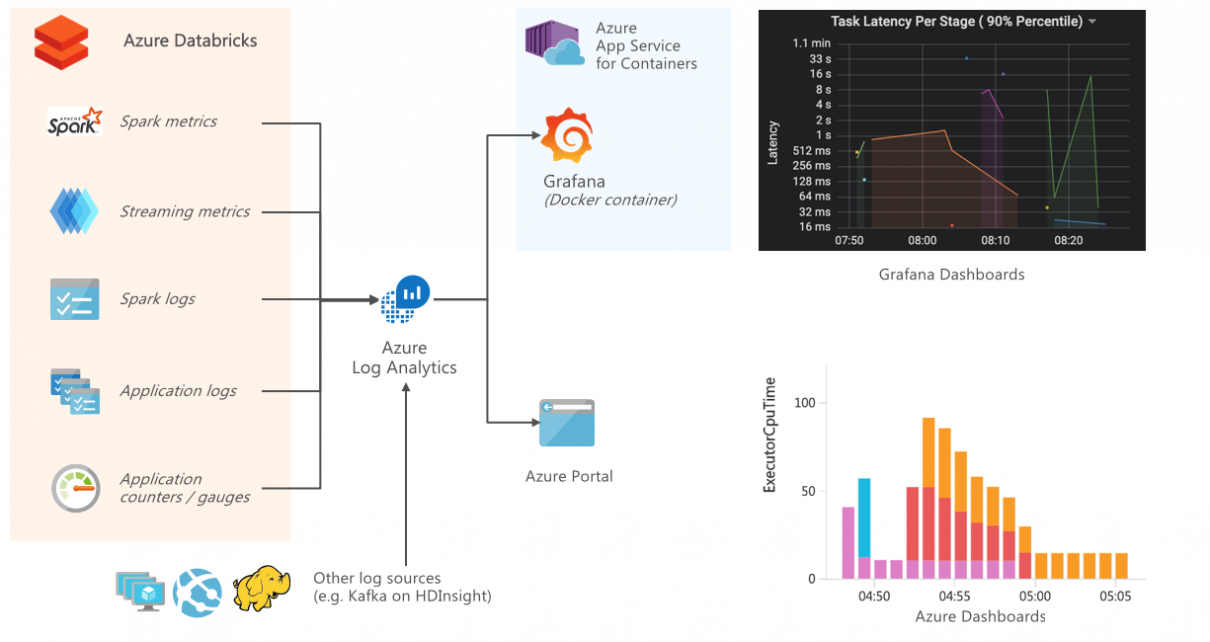
Monitoring and Logging in Azure Databricks with Azure Log Analytics and Grafana
Connecting Azure Databricks with Log Analytics allows monitoring and tracing each layer within Spark workloads, including the performance and resource usage on the host and JVM, as well as Spark metrics and application-level logging. You can easily test this integration end-to-end by following the accompanying tutorial on Monitoring Azure Databricks with Azure Log Analytics and […]
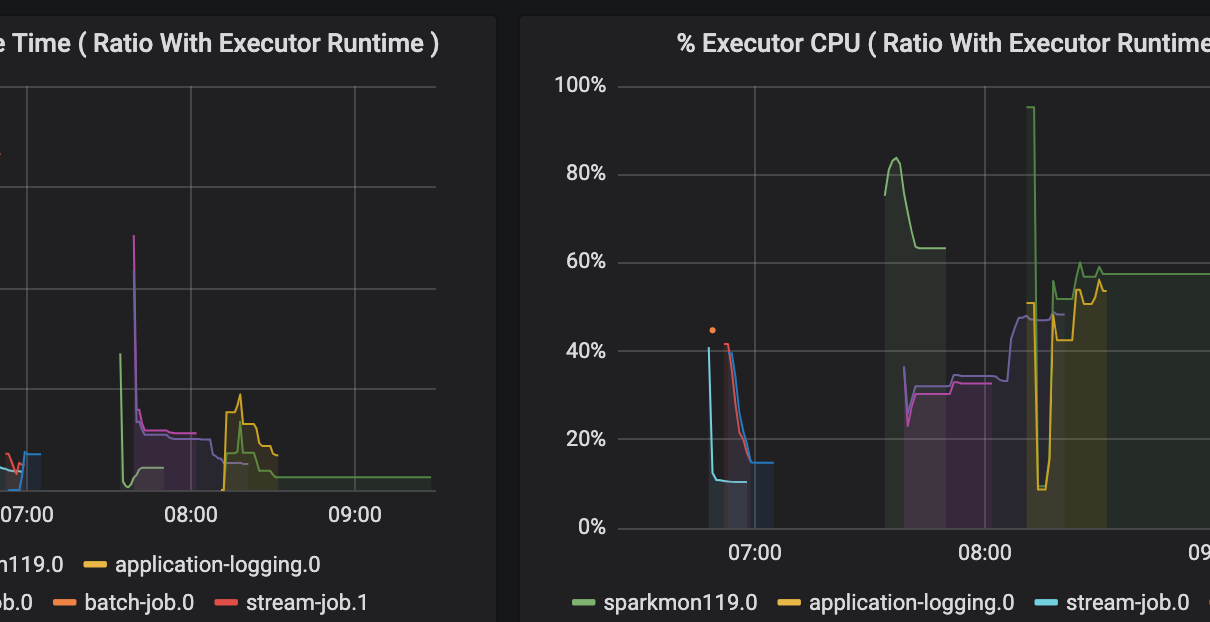
Tutorial: Monitoring Azure Databricks with Azure Log Analytics and Grafana
This is the second post in our series on Monitoring Azure Databricks. See Monitoring and Logging in Azure Databricks with Azure Log Analytics and Grafana for an introduction. Here is a walkthrough that deploys a sample end-to-end project using Automation that you use to quickly get overview of the logging and monitoring functionality. The provided […]