As a Cloud & AI Architect at Microsoft, my customers often identify field service as one of the first application areas for introducing Artificial Intelligence in their businesses. Especially with remote equipment, many companies are frustrated with the impact of downtime due to recurring causes that can be resolved quickly, but require a field service visit to diagnose and repair. Internal experts can often point to patterns correlated with incidents, and the question arises whether a statistical model could learn those patterns from the data. That said, AI is a journey and most enterprises will need to modernize their information architecture before they can engage on ambitious machine learning efforts such as building models for predictive maintenance. In contrast, capturing existing knowledge into AI systems can often drive initial successes and pave the way for further investments.
Table of Contents
AI for predictive maintenance
Artificial intelligence as broadly deployed today mostly falls into two categories:
- Expert systemsapply explicitly programmed rules to mimic the decision-making process of a human expert. They are widely used, for example, to drive clinical decisions at healthcare providers. The rules are usually explicitly programmed based on a model of the expert knowledge. This modeling can be assisted by data mining methods which can propose rules based on statistically significant patterns emerging in the data.
- Machine learningtrains statistical models to perform predictions, based on no more than a set of labeled training data. In practice, however, extensive domain knowledge is often captured in the process of feature engineering. For example, when dealing with predictive maintenance, most machine learning methods are not able to train themselves based on a series of events. Rather, the data engineer must transform these raw data into domain-relevant values such as uptime or time between correlated events. Only then can the dataset be passed to a machine learning training algorithm.
Expert systems were the first form of AI to be widely used in concrete applications such as medicine and engineering. Recently, machine learning has become widespread thanks to advances in theory as well as computing power.
Input data
The availability, consistency and systematic management of data required for maintenance processes often appears to be an afterthought in systems design. Labeling equipment on a pharmaceutical production line, or an ATM in a bank, are more or less guaranteed to shut down in a controlled manner as soon as their sensors detect that they are functioning properly, rather than start printing expiration dates in the past or shredding banknotes. That is because companies subject such procedures to painstaking requirements analysis, quality assurance and validation protocols.
Those processes are usually driven by regulations, and heavily tailored to preserve the safety of human beings as well as the security of assets. Unfortunately, companies do not normally give much thought to the fact that the failing machines in question will also need to be assessed and repaired by a service engineer before they can be restored into service. As a result, service engineers often need to dump many configuration and log files from the machine into a separate computer, and manually delve into them to identify the symptoms and ultimately the cause of the failure.
Software engineers who follow a very structured approach in implementing the core functionality of a system, may not be so diligent when deciding which information gets logged, and that the logged information is consistent, stable over time and in a structure usable by humans and machines alike.
Preparing a training dataset for machine learning requires a consistent, sufficiently large collection of observations that are correctly labeled. The label might be for example, “engine broken” or “engine not broken”.
- Label quality. Obtaining consistently labeled data might be a challenge. Two people, even at a high level of skill, might differ on whether a specific equipment should be labeled faulty in a particular instance, as well as to the nature of the fault. The labels might vary at different times or with different teams. There may be sources of biases from operators enticed to over- or underestimate the incidence of faults for a variety of reasons.
- Data volume and representativeness. Often there may not be a sufficient number of instances of a particular failure mode for the machine learning model to adequately generalize, or the instances might be highly dependent. For example, a set of 10 failures of a particular component may well have 8 instances from one specific equipment whose operator was not competent. The machine learning model is much more likely to predict that this failure mode is related to that particular equipment or operator, than to be able to infer the actual cause of the failure in that scenario.
Training a machine learning model often requires a training set of dozens, if not hundreds of instances of observations that are correctly labeled and consistently represented. Observations should contain a balance of ‘positive’ and ‘negative’ cases (e.g. equipment failure and non-failure situations) and be fairly representative of the actually occurring states of the instrument.
Corrective maintenance
Assembling a training set of good quality for training predictive maintenance models, i.e. being able to predict a failure before it happens, can be very difficult and time-consuming.
In contrast, we have the option of focusing our initial efforts on building a diagnostic aid to corrective maintenance: given a piece of equipment has failed, can we predict from the equipment data what the failure mode and root cause was, and suggest a maintenance action? This is a very concrete and relatable question for teams of service engineers.
As diagnostic is generally a prime skill and highly trained activity for service personnel, such there is often a ‘library of knowledge’ in the organization, in the form of field manuals, notes or in people’s minds, that can be tapped to define predictive rules.
From a first exploration it is usually possible to define clear, measurable success criteria. Rather than “reduce overall cost of maintenance by 5%”, in itself a worthwhile strategic goal, it’s best to start with directly measurable goals for a PoC, e.g. “in those 5 situations, reduce the average time to diagnostic from one hour to 15 minutes”.
Defining the rule set
As such it is usually possible to obtain specifications for the system through structured discussions with experienced service engineers and other experts. A business analyst role should be appointed and be skilled with expressing functional requirements.
For example, the stakeholder might express a rule as “If A happened and then B, and then the equipment failed, then a likely cause is X” and believe the rule has been completely and unambiguously specified. However, that is by far insufficient to program such a rule: is there a minimal and maximal duration between A and B? What happens if A’ occurred between A and B? If B occurred twice?
Implementing the rules
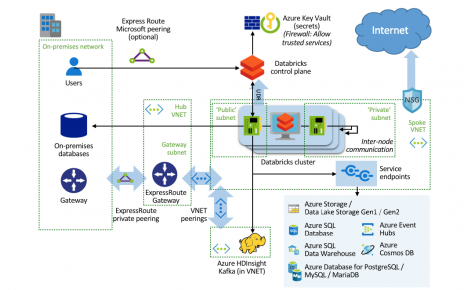
The field equipment may be connected to Azure IoT Hub and continuously stream data. That configuration is recommended to enable remote monitoring, realtime predictive maintenance, etc. Alternatively, for non-connected equipment, equipment data including log information can be uploaded into Azure by the equipment user or the field engineer, upon notification of equipment failure.
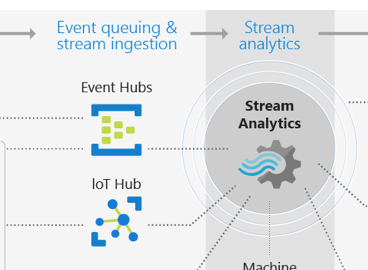
For processing the events, Azure Stream Analytics (ASA) can be leveraged. ASA can connect to IoT Hub (or Event Hub) and apply event aggregation, correlation, complex event processing and custom logic to a stream of events.
Programming
Here is a sample Stream Analytics query to detect “A” events filtering by their Value, correlating two “A” events with a lag of 2 (separated by another “A” event), and with a “B” event with a certain Value in between.
WITH a_events AS
(
SELECT *,
lag(EventTime, 2) OVER(
PARTITION BY Machine LIMIT DURATION(minute, 10) WHEN Type = 'A'
) AS window_start,
EventTime AS window_end
FROM [events] TIMESTAMP BY EventTime
WHERE Type = 'A'
AND Value = 2
AND lag(Value, 2) OVER(
PARTITION BY Machine LIMIT DURATION(minute, 10) WHEN Type = 'A'
) = 0 ),
b_events AS
(
SELECT *
FROM [events] TIMESTAMP BY EventTime
WHERE Type = 'B'
AND Value = 6 )
SELECT a_events.window_start,
b_events.EventTime AS b_time,
a_events.window_end
INTO [matches]
FROM b_events
JOIN a_events
ON datediff(minute, b_events, a_events) BETWEEN 0 AND 2
AND b_events.EventTime BETWEEN a_events.window_start AND a_events.window_end
The query can be conveniently developed and tested in Visual Studio with local data, using the Azure Stream Analytics tools for Visual Studio extension. After it has been confirmed to work locally, it can be seamlessly deployed to Azure and integrated into an IoT solution.
Conclusion
Building an expert system can be an effective way to deliver value from IoT data when expert knowledge can be tapped into, especially when machine learning cannot be applied in a straightforward manner because of lack of labeled data and or when modeling events that rarely occur in the training data. One advantage over machine learning is that expert knowledge is explicitly captured and modeled, which avoids the opacity of many machine learning models. This can help build confidence in the predictive approach, and foster support for scope extensions, such as retrofitting devices with IoT to capture much more data and allow machine learning to be applied.