This is part 2 of our series on event-based analytical processing.
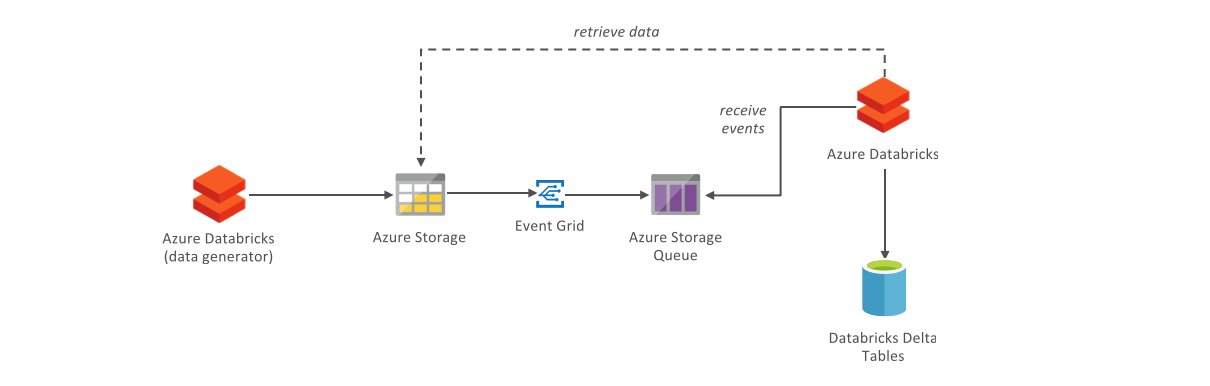
In the previous article, we covered the basics of event-based analytical data processing with Azure Databricks. This tutorial demonstrates how to set up a stream-oriented ETL job based on files in Azure Storage. We will configure a storage account to generate events in a storage queue for every created blob. Then, we will write a Databricks notebook to generate random data periodically written into the storage account. We will write another Databricks notebook that will use the ABS-AQS mechanism to efficiently stream the data from storage by consuming the queue, perform a simple ETL transformation and write aggregate data into a Databricks Delta table.
Table of Contents
Event sourcing
In the Azure Portal, create a Storage Account with all options as default. In the Storage Account, navigate to Blobs and create a new Container called inbound-data. Navigate to Queues and create a new Queue called inbound-data-events.
Navigate to Events and Create a new Event Subscription.
As name, enter inbound-data. As Event Types, deselect Subscribe to all event types and select only the Blob Created event type. As Endpoint Type, select Storage Queues. As Endpoint, select the Queue you just created.
Navigate to the Filters tab. Check Enable subject filtering . In the Subject Begins With field, type:
/blobServices/default/containers/inbound-data/blobs/temperature-data/
Then click Create to activate the Event subscription.
Data generator
Create a new Databricks workspace. In the workspace, create a new Cluster, leaving all options default. Create a Scala Notebook named generator with the following content.
val storageAccount = "YOURSTORAGEACCOUNT"
val storageAccountKey = "YOURSTORAGEACCOUNTKEY"
val credentials = Map(s"fs.azure.account.key.$storageAccount.blob.core.windows.net" ->
storageAccountKey)
dbutils.fs.mount(
source = s"wasbs://inbound-data@$storageAccount.blob.core.windows.net/",
mountPoint = "/mnt/tutorial-inbound-data",
extraConfigs = credentials)
import org.apache.spark.sql.ForeachWriter
import org.apache.spark.sql.Row
import java.io.File
import org.apache.commons.io.FileUtils
import java.util.UUID.randomUUID
import java.nio.charset.StandardCharsets
val inputDf = spark.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
inputDf.createOrReplaceTempView("stream")
val dest = "/mnt/tutorial-inbound-data/temperature-data"
val lineToJsonFileWriter = new ForeachWriter[Row] {
override def process(value: Row): Unit = {
val outputFile = new File(s"/dbfs/${dest}/" + randomUUID().toString + ".json")
val json = value.getString(0)
FileUtils.writeStringToFile(outputFile, json, StandardCharsets.UTF_8)
}
override def close(errorOrNull: Throwable): Unit = {
}
override def open(partitionId: Long, version: Long): Boolean = {
FileUtils.forceMkdir(new File(dest))
true
}
}
val eventDf = spark.sql("""select to_json(
struct(value as row_id,
int(RAND()*100) as site_id,
int(RAND() * 1000)/10 as temperature)
) as json from stream""")
val streamingQuery = eventDf
.writeStream
.foreach(lineToJsonFileWriter)
.start()
Replace YOURSTORAGEACCOUNT and YOURSTORAGEACCOUNTKEY with your storage account name and key. Run each cell in the notebook. The last cell will run until stopped.
Data processor
Leave the notebook running and create a new Scala Notebook named processor with the following content.
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.streaming._
val storageAccount = "YOURSTORAGEACCOUNT"
val storageAccountKey = "YOURSTORAGEACCOUNTKEY"
val schema = StructType(Seq(
StructField("row_id", LongType),
StructField("site_id", LongType),
StructField("temperature", DoubleType)
))
spark.conf.set(
s"fs.azure.account.key.$storageAccount.blob.core.windows.net",
storageAccountKey)
spark.conf.set("spark.sql.shuffle.partitions", "1")
val stream = spark.readStream
.format("abs-aqs")
.option("fileFormat", "json")
.option("queueName", "inbound-data-events")
.option("connectionString", s"DefaultEndpointsProtocol=https;AccountName=$storageAccount;AccountKey=$storageAccountKey;EndpointSuffix=core.windows.net")
.schema(schema)
.load()
display(stream)
The stream shows the random temperature data from the generator notebook, proving that events were properly propagated. Stop the cell execution by clicking Cancel.
We will now create a Delta table storing the aggregated number of measurements per site, and maximal ever recorded temperature per site. Create a new cell with the following content:
%sql
DROP TABLE IF EXISTS site_temperatures;
CREATE TABLE site_temperatures
(site_id long, highest_temp double, count long)
USING delta
Databricks Delta provides the #upserts-merge-into MERGE statement to very easy aggregate the stream into the table. The MERGE statement allows checking if a record for the site already exists, then either creating it or updating it with custom logic.
ETL to Delta – the incorrect way
A naïve developer might believe it is sufficient to MERGE the data item-by-item in the Delta table. See what happens when you run the code below in your notebook.
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
microBatchOutputDF.createOrReplaceTempView("updates")
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO site_temperatures t
USING updates s
ON s.site_id = t.site_id
WHEN MATCHED THEN
UPDATE SET t.highest_temp = CASE
WHEN s.temperature > t.highest_temp THEN s.temperature
ELSE t.highest_temp END,
t.count = t.count + 1
WHEN NOT MATCHED THEN
INSERT (t.site_id, t.highest_temp, t.count)
VALUES (s.site_id, s.temperature, 1)
""")
}
stream
.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
The process might run fine for a few seconds, but will quickly crash with the following error:
What happened? Spark processing is distributed by nature, and the programming model needs to account for this when there is potential concurrent write access to the same data.
Let us add a cell to view the content of the Delta table.
display(table("site_temperatures"))
Delta provides snapshot isolation ensuring that multiple writers can write to a dataset simultaneously without interfering with jobs reading the dataset. However, Delta does not provide a locking mechanism to allow concurrent writers to serialise their access, as it would lead to a performance bottleneck. Delta uses optimistic concurrency control, which means that transactions will fail by design if two concurrent processes attempt to write to the same record. In addition, there is an inherent race condition in the MERGE process, which we need to resolve.
ETL to Delta – the correct way
In our case, the key to avoiding concurrent writes to the same row is to aggregate the data in our stream in order to write to each row no more than once per micro-batch. Let us replace the last cell with this one:
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
microBatchOutputDF.createOrReplaceTempView("updates")
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO site_temperatures t
USING updates s
ON s.site_id = t.site_id
WHEN MATCHED THEN
UPDATE SET t.highest_temp = CASE
WHEN s.max_temperature > t.highest_temp THEN s.max_temperature
ELSE t.highest_temp END,
t.count = t.count + s.count
WHEN NOT MATCHED THEN
INSERT (t.site_id, t.highest_temp, t.count)
VALUES (s.site_id, s.max_temperature, s.count)
""")
}
stream
.groupBy("site_id")
.agg(
max("temperature") as "max_temperature",
count("*") as "count"
)
.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Rerun the %sql cell to purge the site_temperature table, and then run the modified cell above. Everything seems to run smoothly now. While leaving the stream running, rerun the display() cell. If nothing is shown, wait a few seconds and run the display() cell again.
Scheduling a job
The processor job is currently configured to run continuously, which is good if you need to process the data 24/7 with low latency. Thanks to cluster autoscaling, Databricks will scale resources up and down over time to cope with the ingestion needs.
Let us know suppose it is acceptable that the data could be up to 1 hour old. In that case, we could save considerably by spinning a cluster only every 50 minutes, say, let it process the data in the queue, and shut down. Cancel the current stream execution. Just before the .start() statement, add:
.trigger(Trigger.Once())
Run the cell again. This time, the process will only run for a few seconds and then stop.
You could now create a Databricks job to run the processor notebook every 50 minutes on a new cluster.
Do not forget to shut down your cluster. Because the generator notebook has been left to run in the background, the cluster will not auto-terminate.
Conclusion
We showed how to use Storage account events to populate an Azure Storage Queue with events every time a blob is created. This allows creating streaming jobs processing data from Storage, much more efficiently than by repeatedly listing Storage account files.
In our toy example, the data written to Azure Storage were just tiny files containing event data. It would have been more efficient to write those events directly to Event Hubs rather than Storage. However, you can use the concepts shown here to create full-fledged ETL jobs on large files containing enterprise data, that could for example be copied from your enterprise databases using Azure Data Factory.
Databricks Delta provides important benefits as a data management system when writing ETL processes, in particular, a transactional layer over Parquet storage. ETL logic can be concisely expressed through powerful SQL constructs such as the MERGE statement. However, because data is processed in parallel, the developer must be careful not to break the optimistic concurrency model, and must guard against simultaneous writes to single dataset rows.
In our example, the generator only generates 100 distinct values for site_id, so that there are only 100 rows in the destination Delta table. Therefore, the incorrect code above caused an error to occur very quickly. In realistic scenarios, it is very possible that contention is much rarer, so that the incorrect code might pass all the tests and only cause failures much later in production. Developers must be very careful to prevent such scenarios, by not writing multiple times to single Delta rows in the same micro-batch.