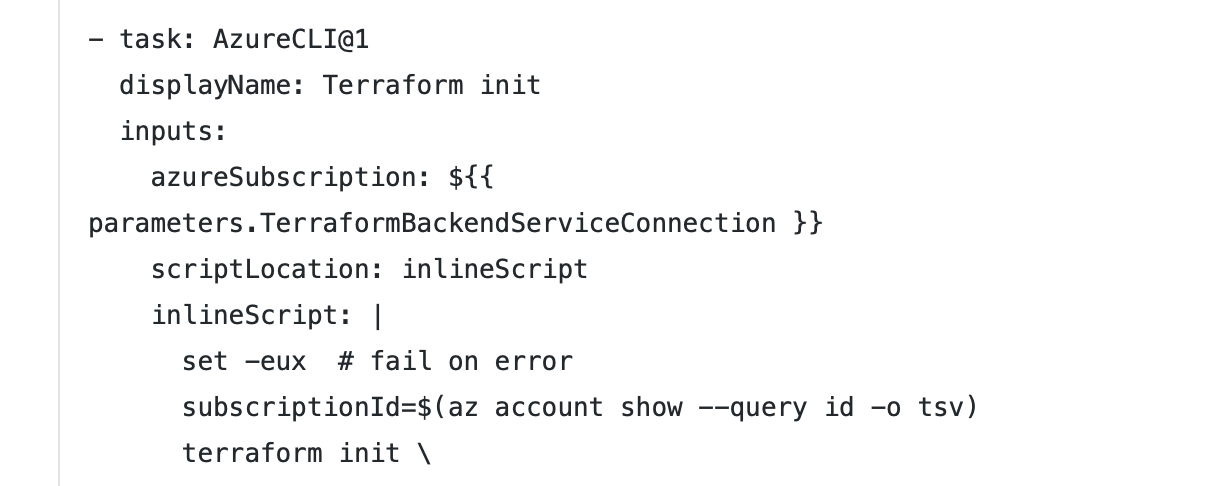
Azure Pipelines offers a variety of extensions for integrating Terraform: An official one from Microsoft which has a number of limitations and has not been receiving any updates for years. A very popular one developed by my colleague Charles Zipp, which offers great functionality, but not all enterprises wish to install community extensions for Azure […]